In Search of an Understandable Consensus Algorithm [Raft]
- Introduction
- Replicated state machines
- What’s wrong with Paxos & Designing for understandability
- The Raft consensus algorithm
- Cluster membership changes
- Log Compaction
- Client Interaction
- Implementation and evaluation, and remaining
Introduction
The problem that Raft is trying to solve is to make consensus understandable by wide audience
Features
- Strong leadership, log entries only flow from the leader to other servers
- Leader election, randomized timers to elect leaders
- Membership changes, joint consensus approach
- when new servers get added with new configuration, they’ll also start executing ops with same order received by old servers, that’s why word “joint”
- both old & new will meet quorum number individually, “jointly reaching consensus”
(Raft is going rambo over Paxos)
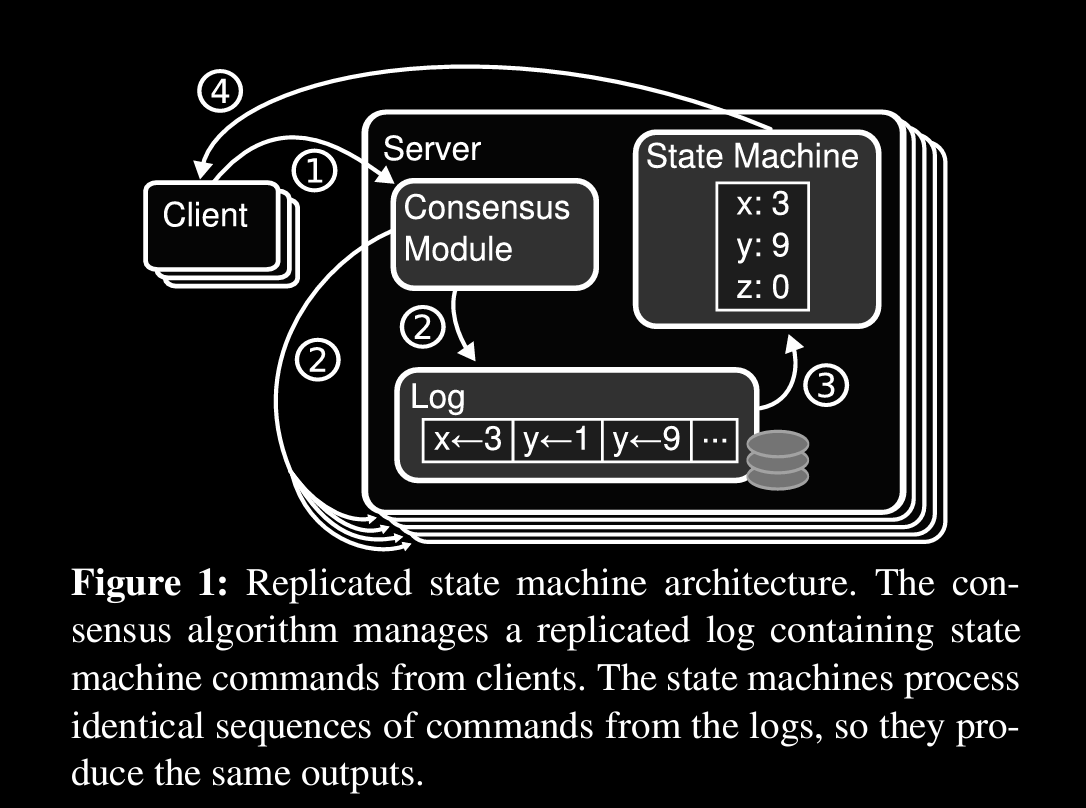
Replicated state machines
Replication is done using a replicated log which contains serial order of commands
Consensus algorithm’s job is to keep log consistent
algo properties
- never return incorrect result (safety)
- availability (liveness)
- don’t depend on timing
- command can be executed once quorum is met
What’s wrong with Paxos & Designing for understandability
- Paxos is exceptionally difficult to understand
- it does not provide a good foundation for building practical implementations
Used randomization to simplify the Raft leader election algorithm
The Raft consensus algorithm
Raft Basics
(Raft Visualization at https://raft.github.io/ & https://thesecretlivesofdata.com/raft/ are best sources to understand the process visually)

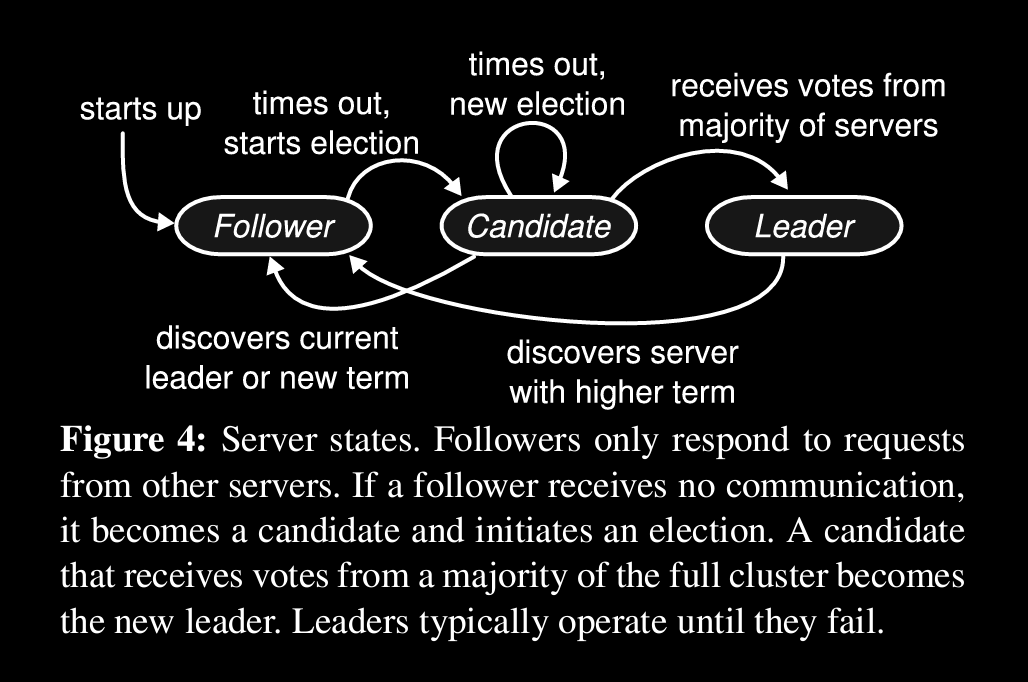
^ state transition diagram
← guarantees raft follows
Each server can be in one of three states
- Leader
- handles client req.s
- will either get req directly or follower will forward incase follower gets req from client
- handles client req.s
- Candidate
- stands in election to become leader
- Follower
-
followers are passive, won’t start any req.s and only respond to leader’s or candidates
-
they try to become candidates when timeout happens
-
Raft divides time into terms of random length
Each server stores currentTerm number (initially 1) which increments over time (once the first leader is elected, increments 2)
If a candidate or leader discovers that its term is out of date, it immediately reverts to follower state
If a server receives a request with a stale term number, it rejects the request.
Basically 2 RPCs are used during consensus
- Candidates can do
RequestVoteRPC, to request vote - Leaders do
AppendEntriesRPC, to append entries to log
third RPC is used to transfer snapshots
Servers retry RPCs if they do not receive a response in a timely manner, and they issue RPCs in parallel for best performance.
Leader Election
each server starts as follower. currentTerm is 1
since timeouts are random, a server will be timed out and becomes candidate then sends RequestVote RPC to all (becoming candidate will increase it’s own currentTerm locally)
if everyone votes, candidate becomes leader and currentTerm becomes 2 at every server
Leader sends periodic heartbeats as AppendEntries RPC that carry no log entries
If a follower receives no communication over a period of time called the election timeout, then it assumes there is no viable leader and begins an election to choose a new leader.
A candidate continues in that state until one of three things happens
- it wins the election
- another server establishes itself as leader
- a period of time goes by with no winner (
currentTermjust goes on increasing)
Each server will vote for at most one candidate in a given term, on a first-come-first-served basis
Once candidate becomes leader, it sends heartbeat msgs to prevent new elections
In between becoming leader, candidate may receive AppendEntries RPC from server claiming to be leader, in that case it’ll check server’s currentTerm which comes in RPC
- RPC server’s term ≥ candidate term, candidate becomes follower
- if <, then candidate rejects RPC
Split votes can happen when 2 candidates are in election, as random timeouts are used, it’s rare
Log Replication
Client sends a request containing cmd to leader
leader appends this in local log, and issues AppendEntries RPCs to followers.
Once replication is done, it’ll commit cmds and return exec result to client
It’ll continuously send RPCs until all followers store all entries
Leader tracks highest idx to be committed, it’s added in AppendEntries RPCs as well
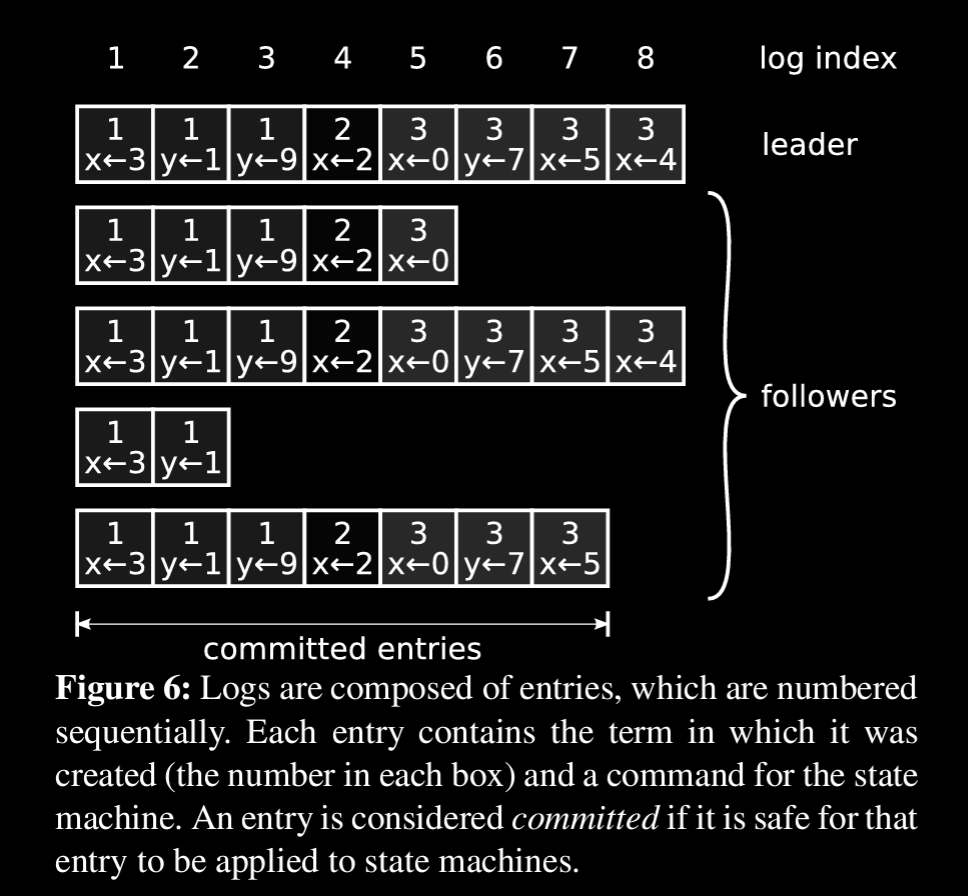

if two entries in diff logs have same idx & term, it means they have same cmd and previous cmds are also same (way of saying identical till that idx)
If the follower does not find an entry in its log with the same index and term, then it refuses the new entries.
But we should assume that any server can crash, incase if leader crashes and new elected leader may not have fully replicated log with inconsistent entries
In Raft, the leader handles inconsistencies by forcing the followers’ logs to duplicate its own (over written)
The leader maintains a nextIndex for each follower, which is the index of the next log entry the leader will send to that follower.
nextIndex helps in in finding idx from where logs got deviated.
As in above fig, leader will send nextIndex 11 in AppendEntries RPC to all followers, if inconsistent, RPC check will fail then leader continues to decrease nextIndex until required idx is found. continuous check can be removed by skipping to idx when term started and checking accordingly
A leader never overwrites or deletes entries in its own log
Safety
There’s a restriction to get elected
- this ensures that the leader for any given term should contain all of the entries committed in previous terms
- (so a leader will have control only on current term cmds)
The RequestVote RPC implements this, it includes information about the candidate’s log, and the voter denies its vote if its own log is more up-to-date than that of the candidate.
If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
(tricky part, follow through highlighted pdf)
Raft never commits log entries from previous terms by counting replicas.
Only log entries from the leader’s current term are committed by counting replicas; once an entry from the current term has been committed in this way, then all prior entries are committed indirectly because of the Log Matching Property.

If a follower or candidate crashes, RPCs sent to them will fail
Raft RPCs are idempotent, so once they’re online again, they can process RPCs (even if an RPC is processed but crashed before responding)
Ideal timing
time taken for broadcasting RPCs (0.5-20ms) << election timeout (10-500ms) << mean time b/w server crashes (days)
Cluster membership changes
for a zero downtime migration from one config to another config (adding/removing servers), raft uses a 2-phase approach, which is Joint Consensus
log entries will be replicated to all servers (which are in both old, new).
any server can serve as leader but consensus will require separate majorities from both the old and new configurations
client req.s won’t be blocked during joint consensus
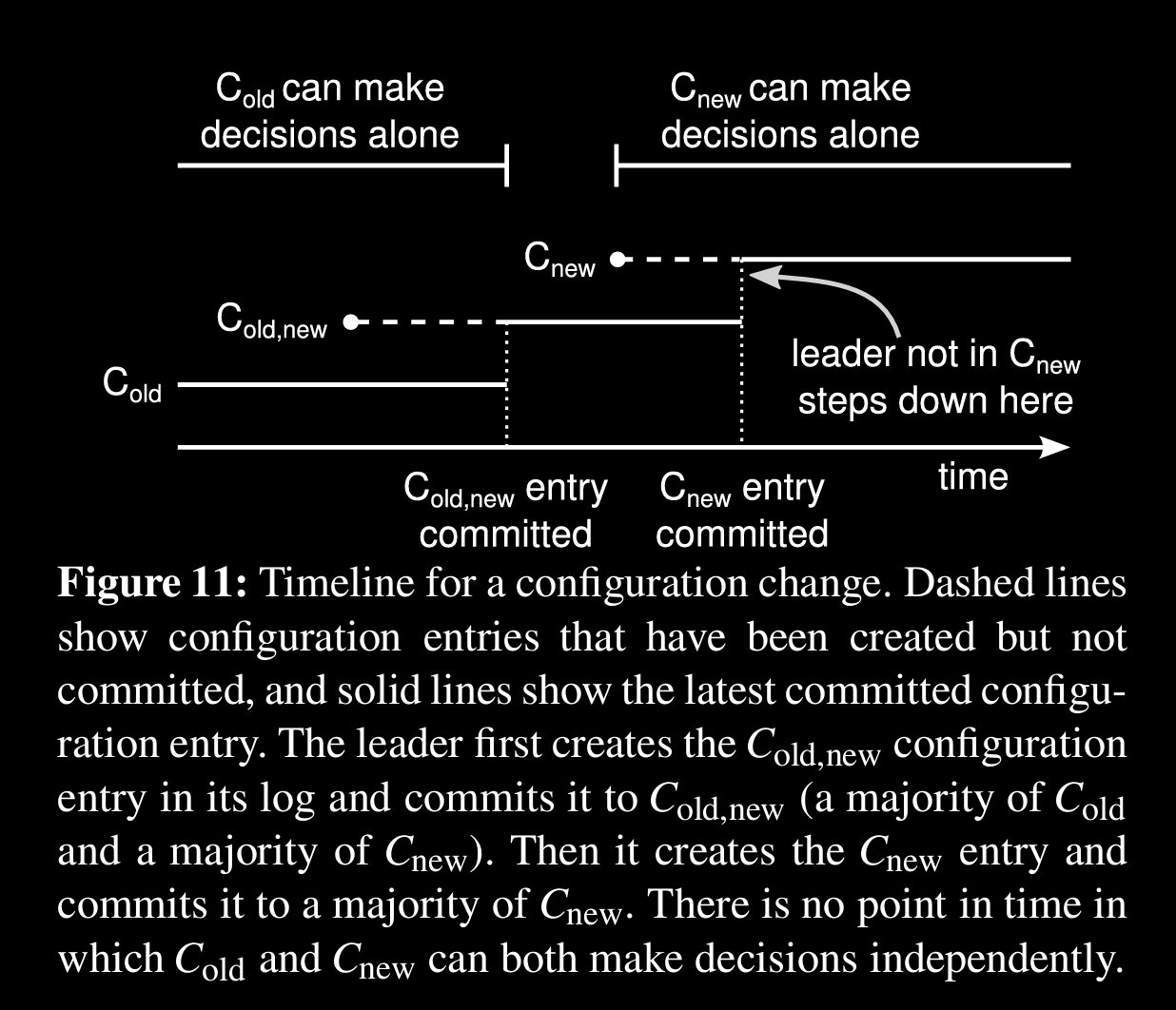
, are old, new configs
when a config change is received, leader will keep both old and new in , it’ll then replicate and commit (with consensus of majority servers from old new configs).
now entries to Cnew will start, after consensus with servers in new config, it’ll commit and it’s back to normal consensus from joint
there is additional phase in raft to avoid availability gaps in which new servers join as non-voting memebers and just gets huge log in order to be in sync
if leader is not from Cnew, it’ll step down from leader to follower
Log Compaction
log becomes longer with time due to client interactions, so compaction should be done
snapshotting is the approach, we can remove redundant info through this and keep log shorter
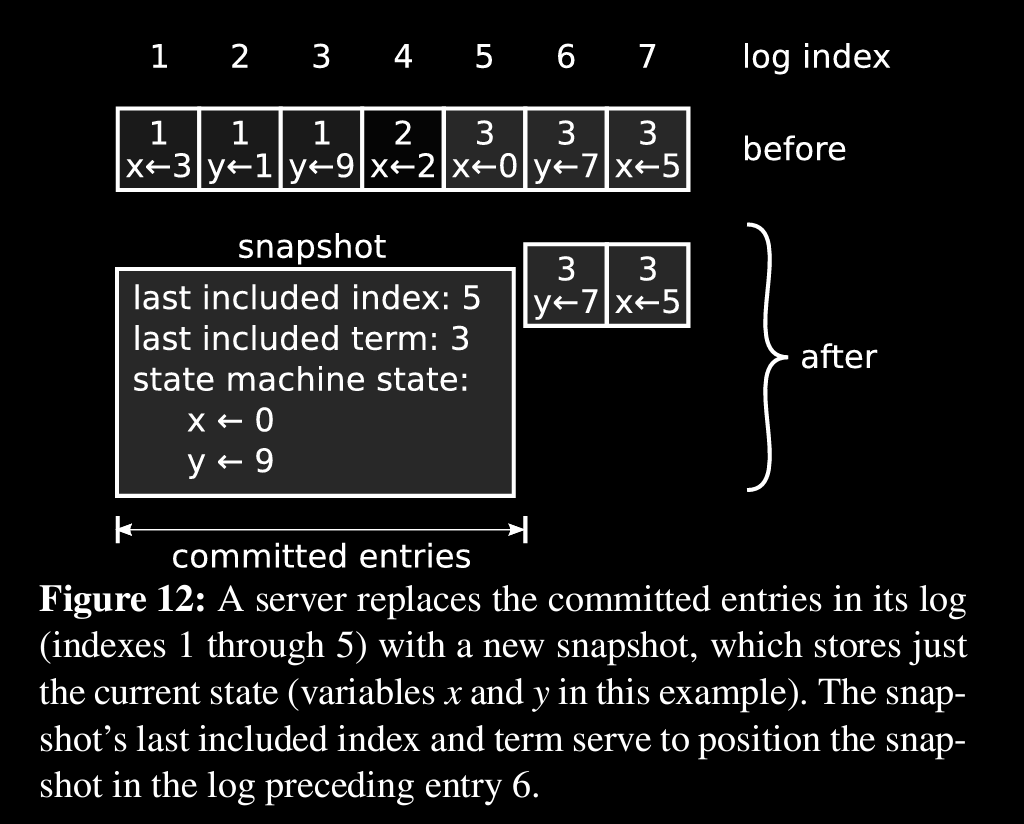
mechanism like lsm tree, log cleaning but requires additional mechanism and complexity
leader can send snapshot instead of all cmds with InstallSnapshot RPC to followers who lag behind so much
Balanced strategy is to take a snapshot when the log reaches a fixed size in bytes.
Client Interaction
Initially client connects to randomly chosen server, which will redirect to leader if it’s a follower
client will retry randomly if leader is not found
linearizability is met as follows
-
a serial num is attached to cmds, if same serial num is received again, it responds immediately without re-executing the request.
Implementation and evaluation, and remaining
from reference pdf