On-demand Container Loading in AWS Lambda
- Notation Legend
- Pre-Read Thoughts
- Introduction
- Block-Level Loading
- Deduplication Without Trust
- Tiered Caching
- Post-Read Thoughts
- Further Reading
Notation Legend
#something: number ofsomething
→: excerpt from paper
(): an opinion or some information that’s not present in paper
Pre-Read Thoughts
(continuing from Firecracker- Lightweight Virtualization for Serverless Applications)
AWS Lambda is a service that most will be familiar with, after S3
Few things ik related to lambda are, one that it uses a custom container solution called Firecracker, and — just like any FaaS — cold-starts
I’ve seen people abusing lambdas to be the entire backend
Lambda refers to anonymous functions, closer to functional programming
Serverless as in “scales automatically as per use” ⇒ cost efficient when not using, but yes, there is server in serverless even
Introduction
Key perf metric is cold start, or the scale-up time
Lambda supports normal functions on uploading a zip archive, and containers like docker also
not only container images can be large but also containers getting deployed, so there are three factors which influence scalability and cold-start
- Cacheability
- large scale-up spikes are driven by small images
- Commonality
- common base layers in images
- Sparsity
- dont need entire container data to load, only 6% on avg
Existing Architecture Overview
(ofc, aligns with Firecracker- Lightweight Virtualization for Serverless Applications’s Architecture)
function Invoke requests are received by frontend (stateless, load balanced) and passed on to Worker Manager
→ Worker Manager is a stateful, sticky, load balancer. For every unique function in the system, it keeps track of what capacity is available to run that function, where that capacity is in the fleet, and predicts when new capacity may be needed.
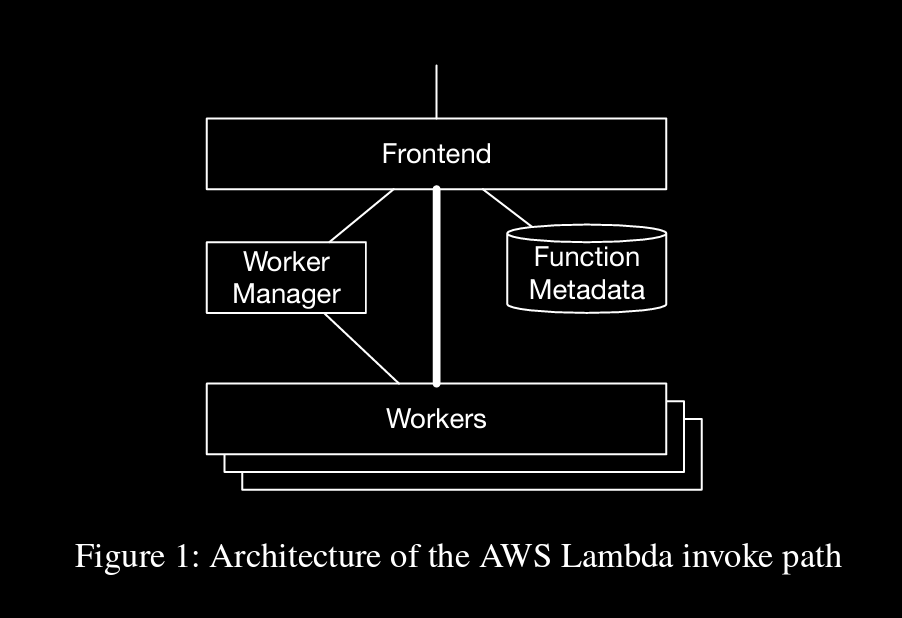
when capacity is available (workers are free), manager sends info of worker to frontend, then frontend directly sends function payload to worker. If cap is not available, a new slot is created and then frontend is notified
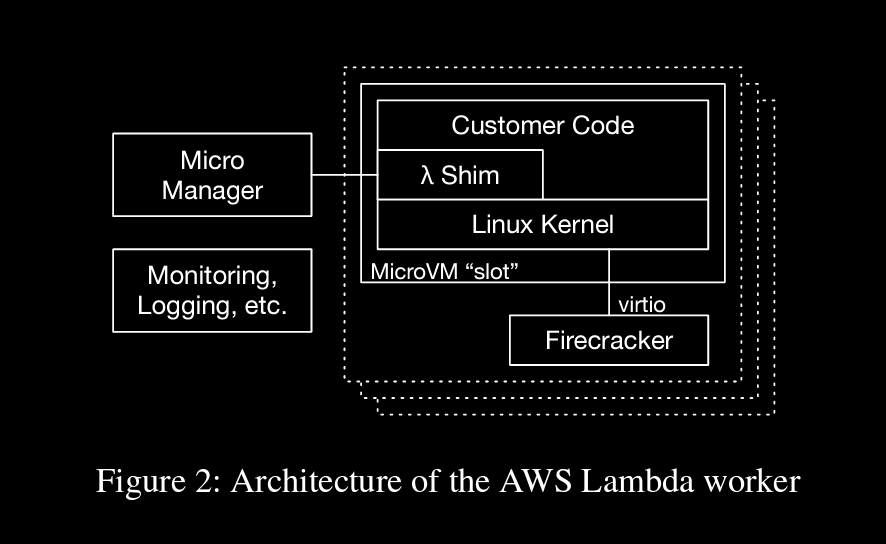
→ Each MicroVM, based on our Firecracker hypervisor, contains the code for a single Lambda function for a single customer
→ a small shim that provides Lambda’s programming model, any provided runtime (e.g. the JVM for Java or CoreCLR for .NET)
virtio (net, block) fro communication b/w microvm and shared worker components
Block-Level Loading
→ To take advantage of the sparsity property of containers, we needed to allow the system to load(and store) only the data the application needs, ideally at the time it needs it
as virtio is being used for security concerns, they’re running virtio-blk interface b/w microvm guest and hypervisor. This requires to load required container data at block level but not file level
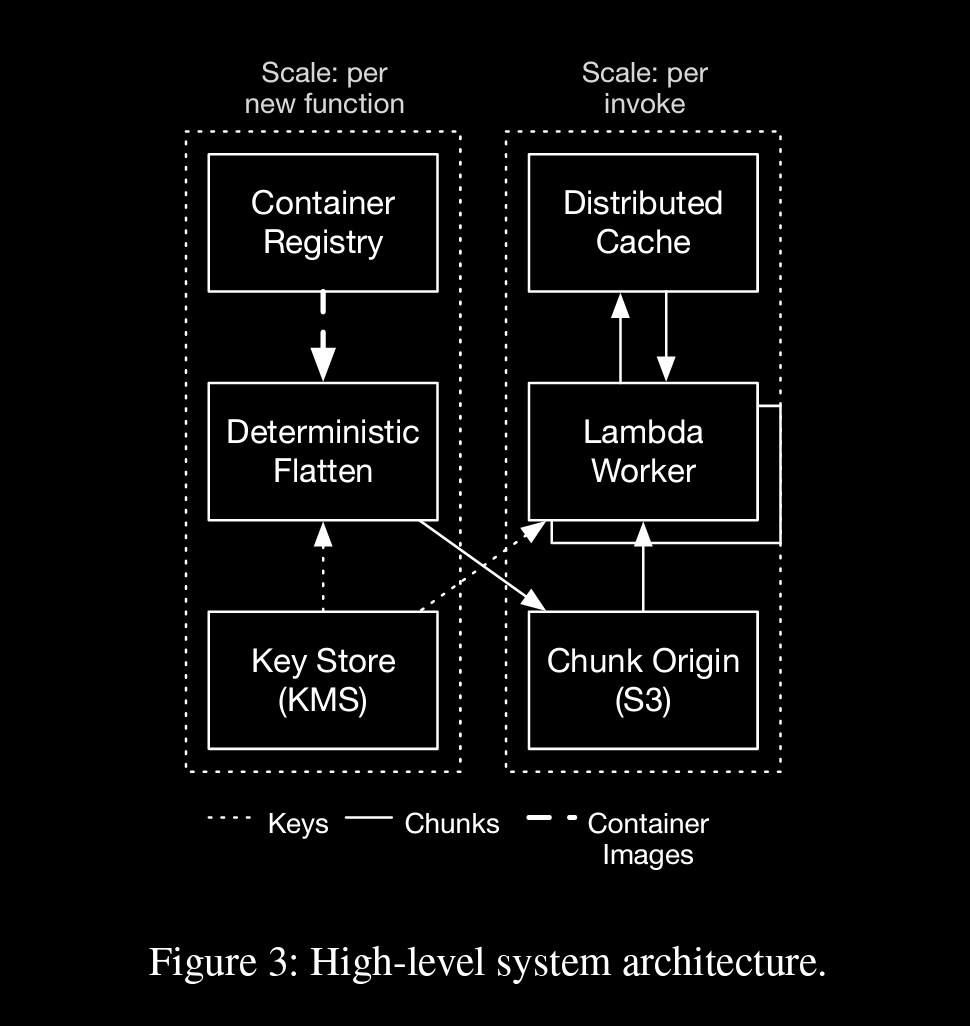
→ Our first step in supporting block-level loading is to collapse the container image into a block device image.
→In our implementation, we perform this overlaying operation at the time the function is initially created, following a deterministic flattening process which applies each tarball in order to create a single ext4 filesystem.
→ Function creation is a low-rate control-plane process, that is typically only triggered by customers when they make changes to their code, configuration, or architecture
(control plane ⇒ decides how data packets should go (optimal routing))
→ the high-level reason is that differences between functions (and even more so between versions of the same function) are typically much smaller than the functions themselves.
once flattening is done, which results in fixed-size chunks (512KB), chunks are uploaded to three-tiered cache (using S3 to store)
(tiered cache ⇒ tiered cache improves cache hit ratios by allowing some data centers to serve as caches for others, in normal scenario has to make a request to the origin, more simply if cache is missed at one tier, it’ll move up in tiers until origin)
a optimal chunk is to be set (currently 512KB) as system evolves because
- smaller the chunk size, better the duplication, since entire chunk need no to be replaced which can be costly if chunk is large
- with larger chunk, metadata size and reqs are reduced ⇒ better throughput
Per-MicroVM Snapshot Loading
→ A per-function local agent which presents a block device to the per-function Firecracker hypervisor (via FUSE), which is then forwarded using the existing virtio interface into the guest, where it is mounted by the guest kernel.
→ A per-worker local cache which caches chunks of data that are frequently used on the worker, and interacts with the remote cache
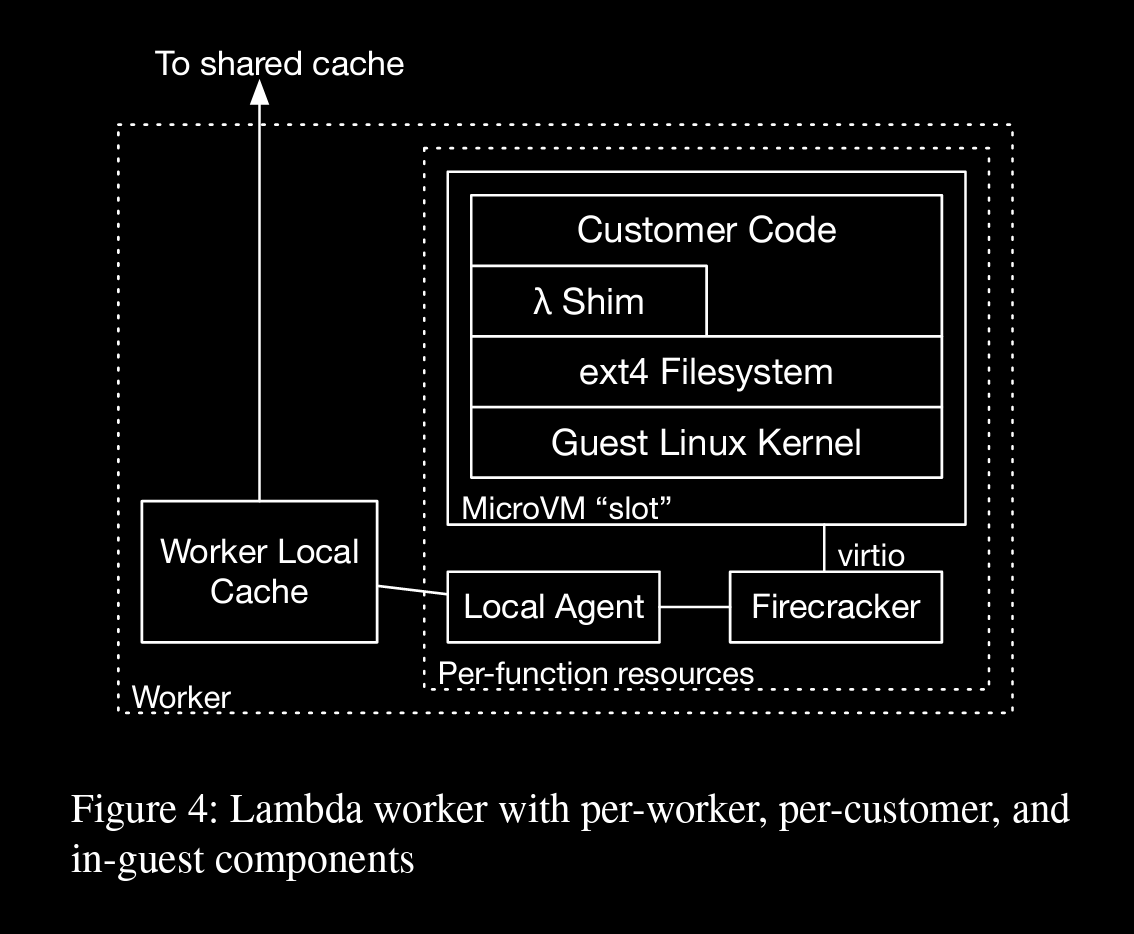
Micro manager creates a new local agent and a FC microVM containing 2 virtio block devices (a root device (same for all microVMs), a device backed by FUSE fs from local agent)
→ The local agent handles write by writing them to block overlay, backed by encrypted storage on the worker. A bitmap is maintained at page granularity, indicating whether data should be read from the overlay, or from the backing container image.
Deduplication Without Trust
80% of functions have same chunks repeated as they come from base images like alpine, ubuntu
So deduplication (removing redundancies or normalizing) is very worth it, it can reduce different resource allocations across the stack
Convergent Encryption
→ A cryptographic hash of each block (.. a chunk of a flattened container image) is used to deterministically derive a cryptographic key that is used for encrypting the block.
→ A manifest of chunks is then created, containing the offset, unique key, and SHA256hashof each chunk2. The manifest is then encrypted, using AES-GCM, using a unique per-customer key managed by AWS Key Management Service (AWS KMS). Chunks are then named based on a function of the hash of their ciphertext, and uploaded to the backing store (AWS S3) using that name if no chunk of that name already exists.
in that manifest, only keys are encrypted but not values (which are encrypted chunks)
this allows GC process to access access chunks without keys
Compression
→ Our system does not compress chunk plaintexts prior to encryption
two reasons for not compressing
- network latency/bandwidth is good enough that compressing won’t effect it significantly
- compression side channel ⇒ potential attackers can access plaintext contents during compression process and get hints on actual data
Limiting Blast Radius
deduplicated chunks
- if that chunk got any issues, so many processes dependent on that chunk will suffer
- popular chunks getting hot-spotted in storage
→ To solve this problem, we include a varying salt in the key derivation step of our convergent encryption scheme. This salt value can vary in time, with chunk popularity, and with infrastructure placement (such as using different salts in different availability zones or datacenters)
Garbage Collection
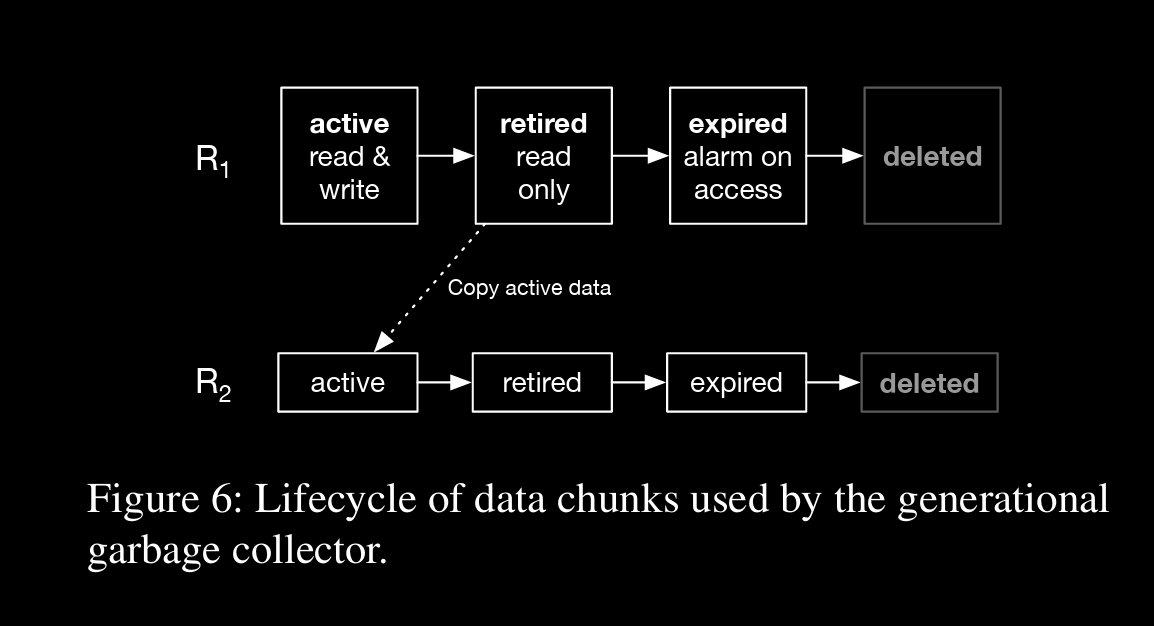
→ Our approach to garbage collection is based on the concept of roots. A root is a self-contained manifest and chunk namespace, analogous to the roots used in traditional garbage collection algorithms.
roots are created periodically and migrated from retired to fresh roots
retired roots are not deleted instantly but moved to expired state where reads can raise alarm
Tiered Caching
Optimizing for Tail Latency
Stability and Metastability
Cache Eviction and Sizing
Post-Read Thoughts
Deduping section is really thought provoking
- Cryptography introduction with convergent enc (I didn’t even think of using encryption)
- GC part is also interesting, where I’m looking beyond mark and sweep
Tiered Caching