Spanner: Google’s Globally-Distributed Database
- Pre-Read Thoughts
- Introduction
- Implementation
- Concurrency Control
- Evaluation
- Post-Read Thoughts
- Further Reading
Pre-Read Thoughts
Heard about Spanner that cockroachdb is inspired from it. (yet another google paper)
Introduction
Spanner → multi-version, globally distributed and synchronously replicated (at the same time, not batched as in async)
it automatically reshards based on amount of data and servers
replication config can be controlled by clients/apps at fine grain level like which DC they want to put data in
read & writes are externally consistent → linearizable
consistent reads at same timestamp
time or clock is maintained by TrueTime server which exposes API
(TrueTime uses a combination of GPS clocks and atomic clocks across the data centers that Spanner runs in)
spanner will slow and wait when clock uncertainty is large
Implementation
A spanner deployment is called universe (the picture on right)
it’ll have different zones which are physically separated
a zone will have zonemaster which assigns data to thousands of spanservers
location proxies know which data is in which spanserver , so redirects clients to correct spanserver
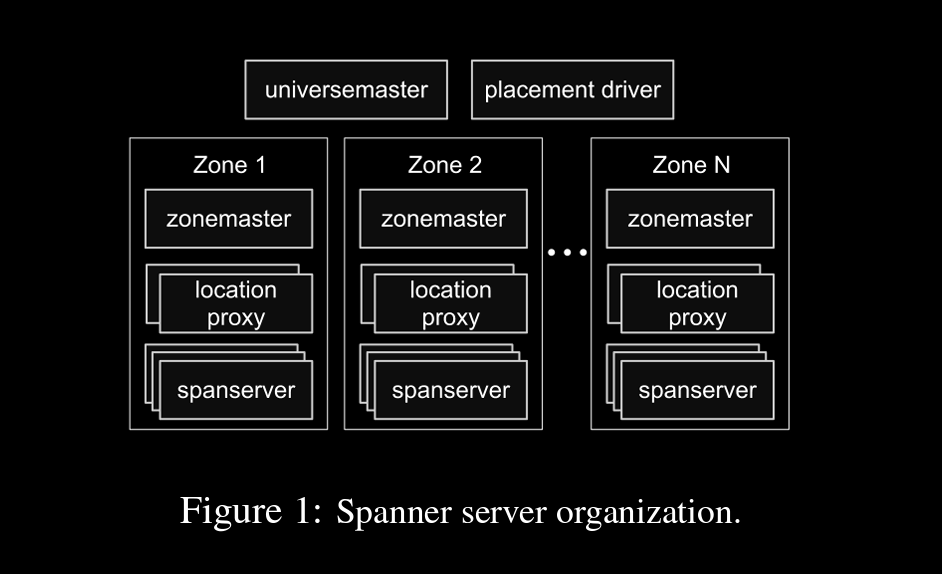
universemaster is console that displays all the info about zones, placementdriver which polls spanserver helps in rebalancing data when config changes
Spanserver Software Stack
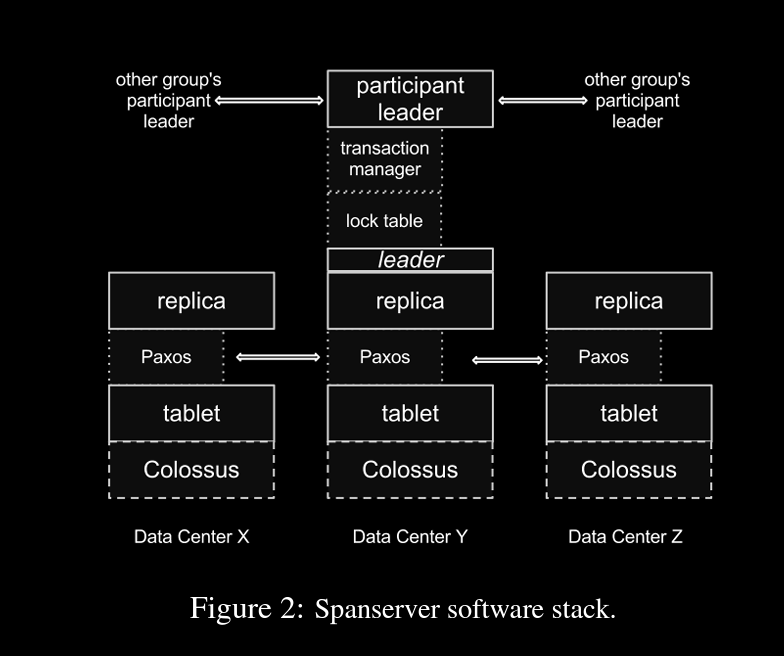
1 spanserver → 100 to 1000s of tablets
a tablet contains many mappings as KKV
(key, timestamp) → value
timestamp ⇒ multi versioning
tablet’s state is stored in colossus (gfs successor) and in WAL
state is replicated using paxos algo as in pic left side, replicas are grouped as Paxos Group
writes happen at leader, reads can be at any replica which is up to date
leader will have lock table containing 2PLs, with range of keys to lock mapping, for concurrency control
when there are multiple paxos groups under same participant leader, transaction manager helps with distributed transactions where group leaders commit 2PC
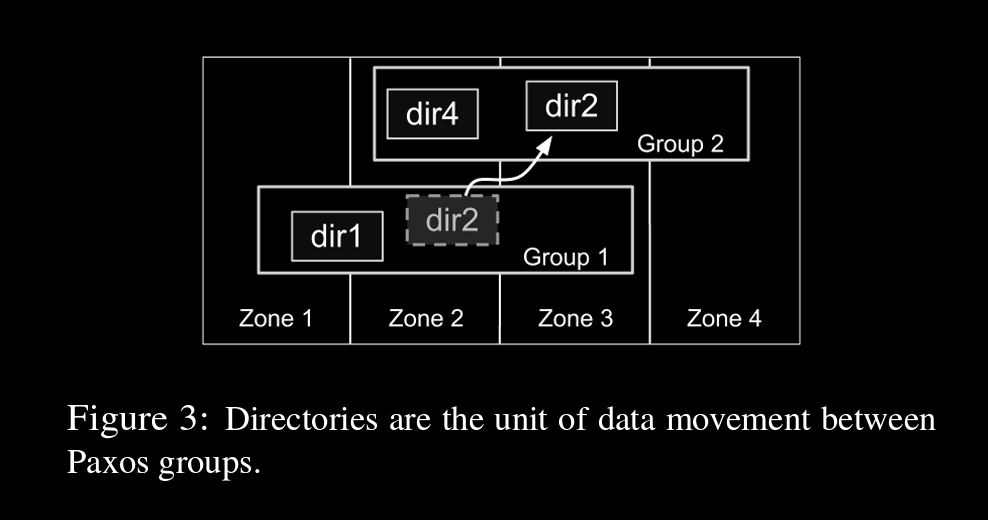
Directories and Placement
tablet can be bucketed under directory
dir contents will have same replication config
a paxos group can have multiple directoriess
contents will be moved to reduce or balance load or make access speeds faster by putting close to accessors
Data Model
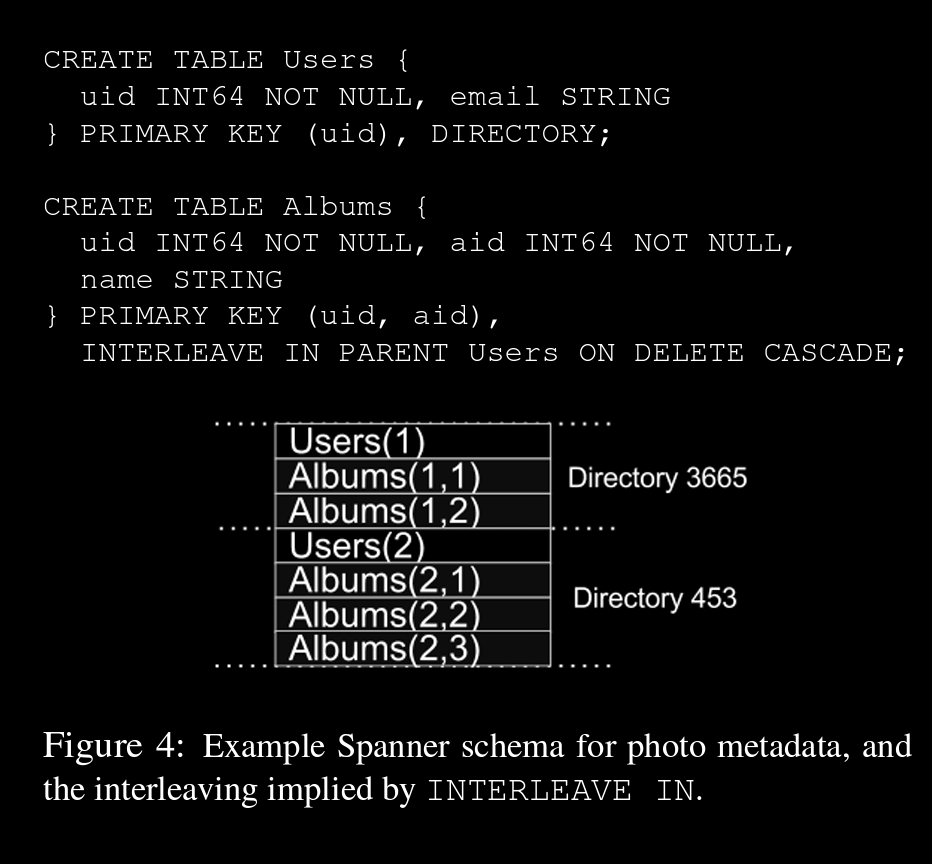
semi relational, query lang similar to sql, general purpose transactions
2pc with paxos makes it simpler with FT
Left side schema showing INTERLEAVE IN with DELETE to delete Albums when User is deleted
TrueTime
TT.now() gives a bounded interval with [earliest, latest], where abs time of event will be in that interval
a time master is maintained across DC, machines have time slave daemons

majority masters return time based on GPS, remaining armageddon masters are based on atomic clocks
daemons will poll diff masters to finalize on accurate time
Concurrency Control

Op.s supported by Spanner
Paxos leader maintains lease for it’s time period as leader, and it’s extended on successful write
disjointness invariant ⇒ at any point of time, there is only one leader
Leader can give up it’s position (abdicating), for that it’ll have complete all the transactions happened till then ⇒ if is max timestamp by leader, it should complete all txs till then and wait until TT.after() is true
RW txs
- reads in the tx don’t see effects of write, as writes won’t committed and kept at client buffer (isolated)
- wound-wait for deadlock avoidance (tx with low priority (latest tx with latest ts) gets aborted)
RO txs
Evaluation
from reference pdf
Post-Read Thoughts
Spanner marks the NewSQL movement
Some concepts are actually a bit tough to grasp. Went to chatgpt with a lot of questions for clarification, I might come back to this paper again sometime in future
Depicts the real world implementation of distributed txs
Really went big time with TrueTime
wrt cockroachdb, raft is used for consensus instead of paxos, which makes sense because there is no raft at the time of spanner