ZooKeeper: Wait-free coordination for Internet-scale systems
Introduction
Problem that zookeeper solve is coordination among services with involvement of consensus
the very high level diff b/w chubby and zk is that chubby is blocking due to locks whereas zookeeper is async
(wait-free ⇒ async, which is the very title of the paper “wait-free coordination”)
with async, perf and throughput increases
ZK is implemented in a FIFO pipelined architecture, simply a queue
In terms of linearizability, reads are not linearizable, only writes/updates are linearizable using total order braodcast or atomic broadcast. Protocol ZK implemented for this is ZAB (Zk Atomic Broadcast)
to increase read perf, data is cached client side
similar to consistent caching in chubby (which is blocking in nature), Zk notifies clients, using watch mechanism, whenever data change happens so clients can update
In chubby, there are leases which are timeouts to overcome lags
chubby is strong consistency, zk is relaxed (AP as in CAP)
paper contains info on
- coordination kernel
- coordination recipes
- xp with coordination
The ZooKeeper service
server is where zk service runs
data is stored in znodes which organized in data tree as in below
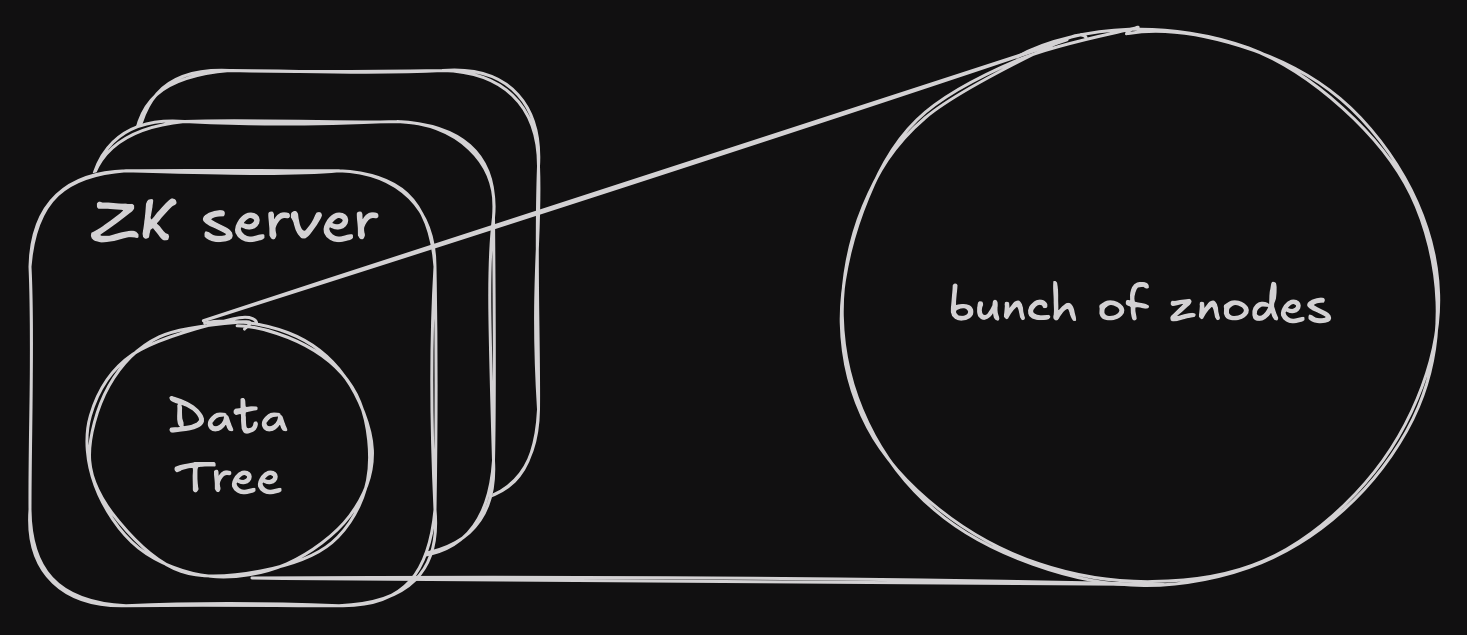
https://excalidraw.com/#json=AsuL2Q_PhRf7FY59PD00M,2hZoF119iMlAwouQdHp_ow
clients get session handle when connected to zk as a session is created
graph LR A["/"] --> B["/app_1"] A --> C["/users"] B --> B1["/app_1/config"] B --> B2["/app_1/servers"] B --> B3["/app_1/status"] B2 --> B21["/app_1/servers/001"] B2 --> B22["/app_1/servers/002"] C --> C11["/users/alice"] C --> C22["/users/bob"]
znodes can store metadata for clients + their own metadata with timestamps + version counters
because of sessions which are global, clients can move from one server to another in ensemble
when creating znode (with API), the flags can be set for
ephemeral(removed when session ends) orregularsequential- a counter to appended to its name like in app_1, app_2
znode can be deleted by sending path & version
znodes can be watched by setting flag in exists() or getData() API call
to write data, setData() along with version number in API call is used
sync() will wait until all the op.s sent by client are completed (as op.s are async)
Guarantees
- Linearizable Writes
- FIFO order for single client’s req.s
Zk’s linearizability → a-linearizability (async)
ready znode exists in zk, which can be used to know state of server
config of a server is only read when ready znode exists
when updating config, leader removes ready , once config is completely written
clients can watch ready, so they’ll get notified when ready is deleted i.e., problem of clients seeing ready (before it got deleted) and then reading config won’t occur
sync() is used to mitigate stale reads, but can be slow
write before read
ZK can be used for
- Config management
- Rendezvous
- rendezvous znode is like a meeting point for multiple clients (workers) to watch changes made by master
- Group membership
- child znodes which are ephemeral can be created under parent znode, whenever child process is failed or ended, child znode automatically removed ⇒ from membership too
- Locks
- ephemeral znode as a lock, all ops can be done by clients on znode/file like for lock
- clients can watch and get notified when lock is released (znode changes)
- Locks without herd effect
- RW Lock
- Double barrier
- where clients must sync at two distinct points
ZooKeeper Applications
- Yahoo’s Fetch Service
- web crawler
- Katta
- distributed indexer
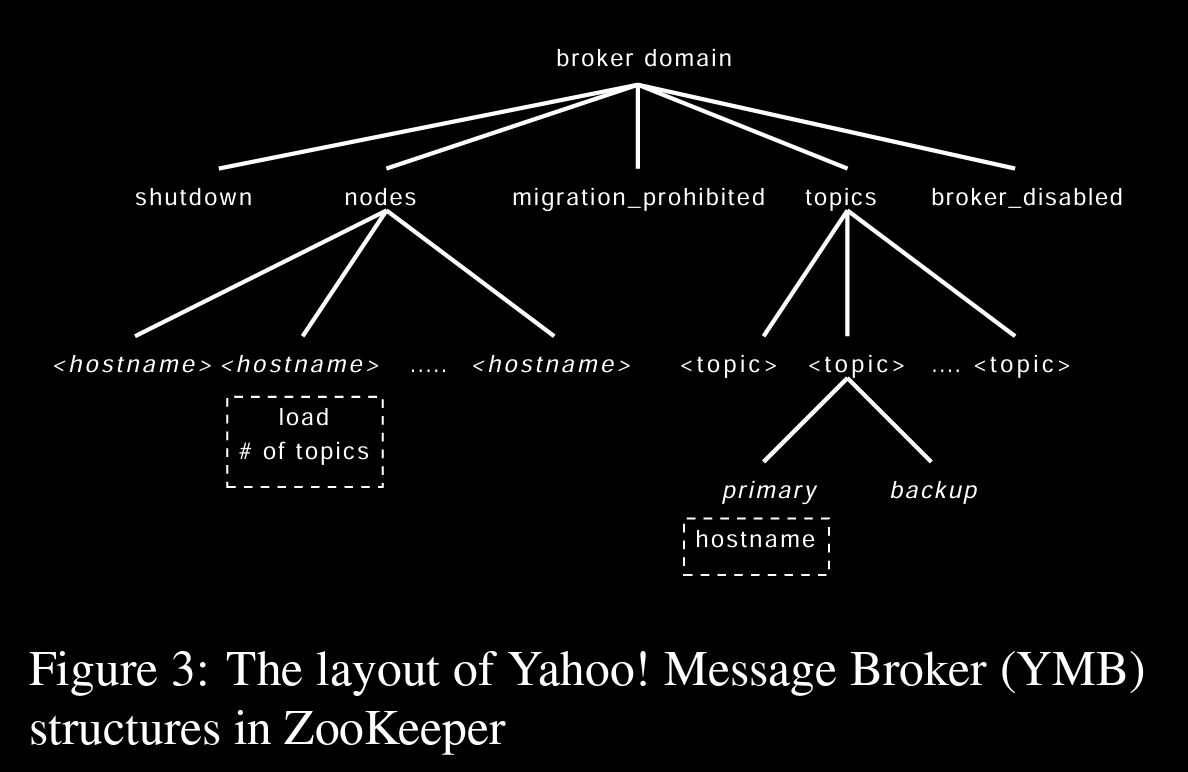
- Yahoo Message Broker
-
distrbuted pub/sub
-
(YMB is parallel with Kafka)
ZooKeeper Implementation
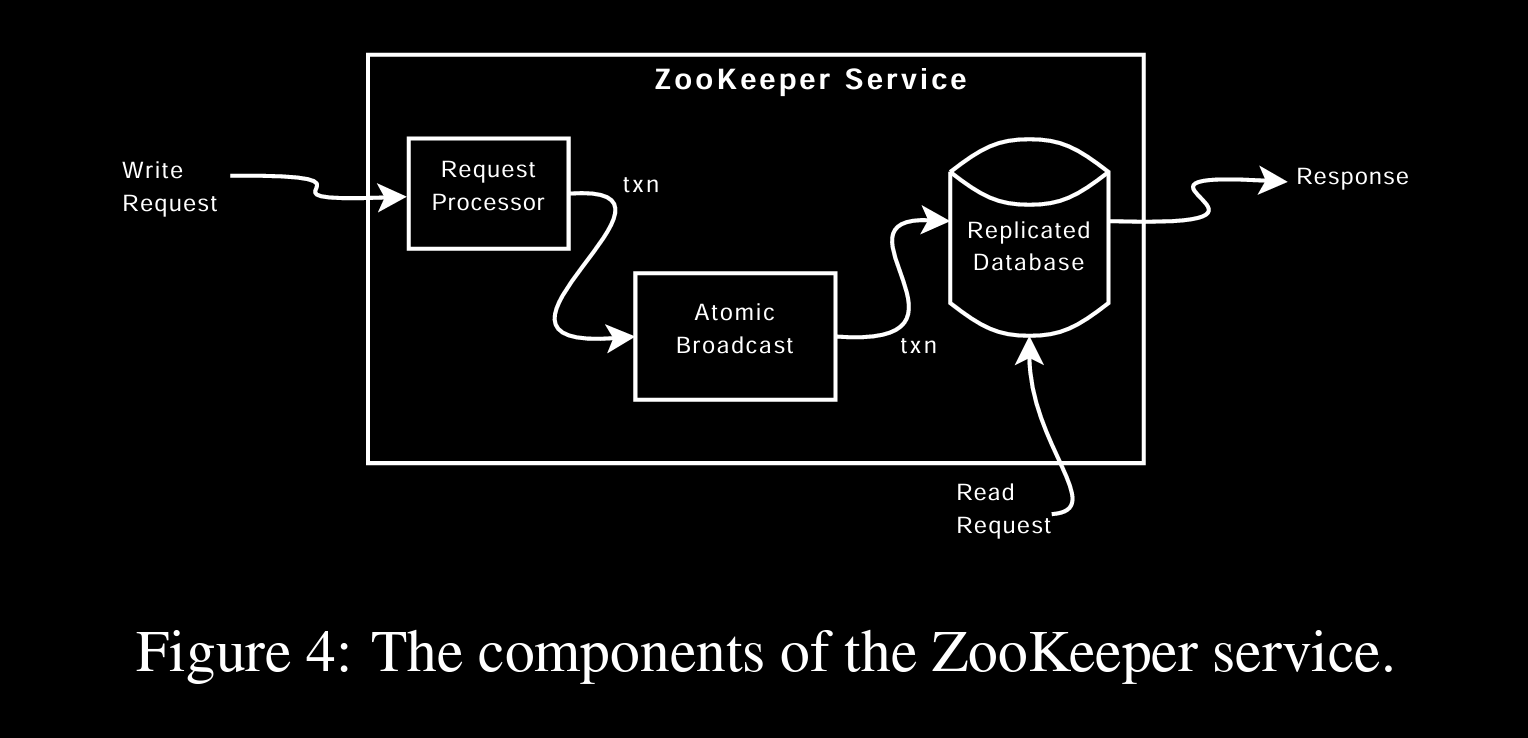
Req Processor is where write req will come to, it’ll start a txn and once quorum agrees, txn will be committed to it’s local replicated db (in-mem).
TO meet quorum, ZK uses protocol called ZAB based on Atomic Broadcast
Read req.s are served directly from local state
Request Processor
Txns are idempotent
When the leader receives a write request, it calculates what the state of the system will be when the write is applied and transforms it into a transaction that captures this new state.
Atomic Broadcast
quorum number for ZAB is similar to others ⇒ 2f+1 to tolerate f failures
Zab guarantees that changes broadcast by a leader are delivered in the order they were sent and all changes from previous leaders are delivered to an established leader before it broadcasts its own changes.
Normally, zab delivers messages in order and exactly once, during recovery, it can redeliver (but idempotent anyway)
Replicated Database
Snapshotting is done, for efficient replaying, which they call fuzzy as ZK state is not locked during snapshot
Client-Server Interactions
server processes writes in order and not concurrently with reads (handled locally)
read req.s are tagged with zxid which relates to last txn seen by server
If the client connects to a new server, that new server ensures that its view of the ZooKeeper data is at least as recent as the view of the client by checking the last zxid of the client against its last zxid.
Evaluation
directly from notes’ reference