In case you’re unexpectedly seeing this page, you might have hit
-
urls subdomain of gowthamkalla.com
-
a non existent route (404) after urls subdomain
if required, you can contact at any of my socials
[WIP]
Have Tea, First
URL Redirector runs at urls subdomain of gowthamkalla.com using Cloudflare Workers
and also got configured for redirects of some paths from gowthamkalla.com, using _redirects, as it runs on Cloudflare Pages
for example, gowthamkalla.com/papers is actually urls.gowthamkalla.com/papers under the hood
Choosing Language & Platform
Initially, Redirector ran on Vercel Functions, and I chose to write it in Python using FastAPI. However, cold starts worsened over time, and I planned to switch.
When I chose Vercel at that time, it was a good option. I had the choice of Cloudflare Workers even then, but I didn’t choose it due to some support incompatibility, I think.
And when choice evaluation came again, it seemed that Workers received a lot of updates in the last couple of years. Though support for Python is still in beta.
Workers support JS, TS, Python, Rust using WASM Runtime API [at current time of writing i.e., Oct 2024]. Since WASM, Web Assembly, can be used, it’s possible to write in any compiled language say Go or C.
Whatever the code that’s already written can be transferred to Workers as Python is supported but in Beta. I thought to dump Python. Rewriting logic shouldn’t take much time as it’s simple URL redirector.
Considering another language, Rust is also fine choice. But it’s also in beta and not performant on workers from what I’ve read.
So plain old JavaScript it is
Started working on PoC script in JS to test & migrate when ready
Designing the Data Structure & Algorithm
Radix Tree, Patricia Trees, Tries?
Let’s start with Index Node, the idea behind naming it as index node is because it acts like index to other index nodes. (huh?)
Though there is a collision between current name & unix fs’ inode, it doesn’t exactly resemble inode, as an inode doesn’t contain inodes inside it, only metadata.
obviously only operation needed is search and no inserts or deletes are required
Iterative approach is very strongly preferred over recursion, most of the time.
Not only that, deep recursion consumes extra stack space i.e., possibility of hitting OOM but also idealizing from code is tricky. This project won’t go that deep though.
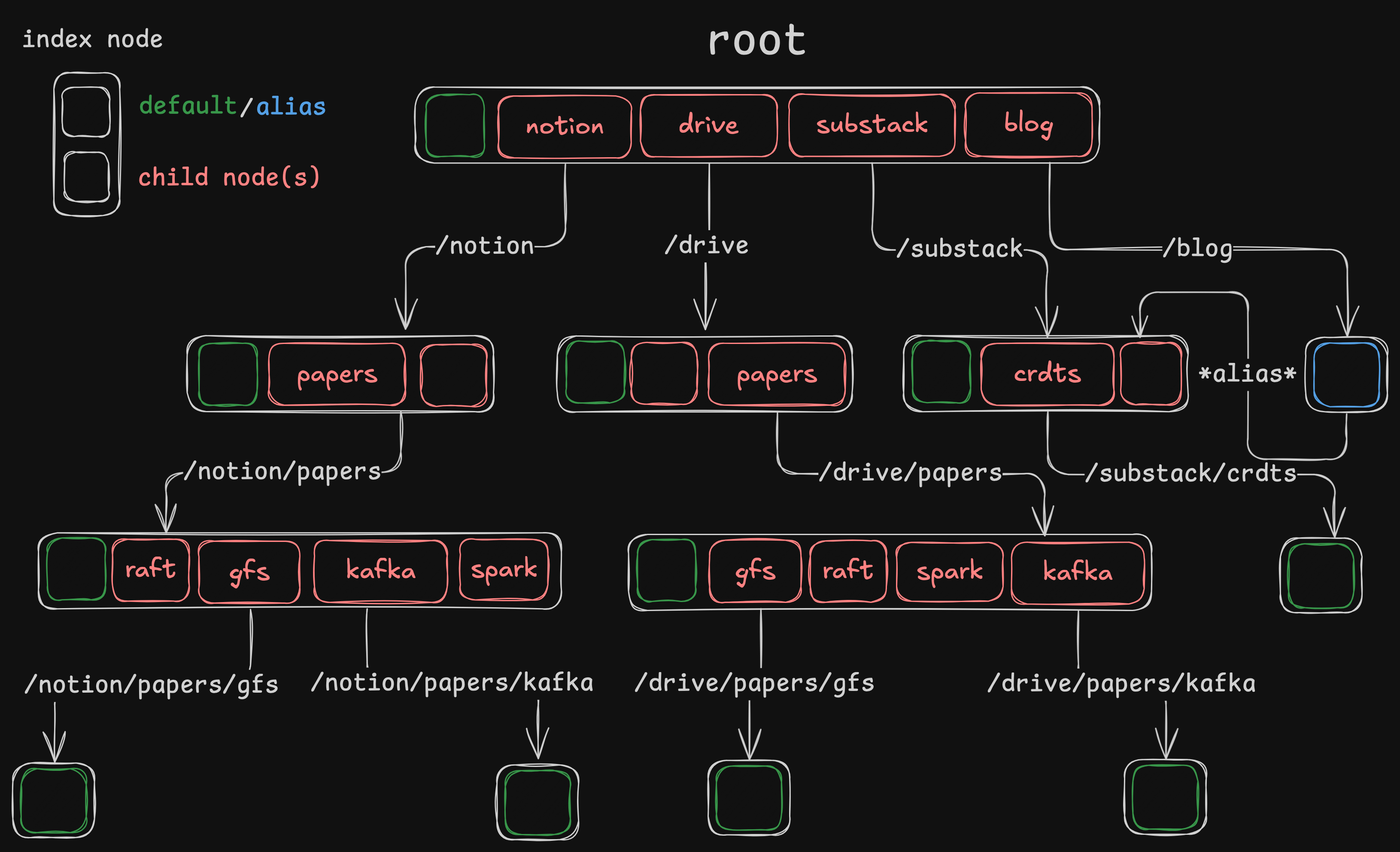
https://excalidraw.com/#json=yDU8FavYRv-26O0O7OEXH,Z-zK6g1az1ZoMcvG2PTs-A
Search Algorithm
This is some part of my worker.js to understand core functionality
You can also run this at https://onecompiler.com/javascript/42x2fky4m
const urlSplit = request.url.split("/")
const reqPathParts = urlSplit.slice(3)
const reqPath = reqPathParts.join("/")
...
function search(parts) {
let current = routes;
let lastValidValue = current.default;
for (const key of parts) {
// check if curr key is present
// if present there will be either default or it is an url
if (current[key] !== undefined) {
current = current[key];
// update last valid to curr, if curr is an url
if (typeof current === 'string') {
lastValidValue = current;
} else {
// else update last valid to curr default
// this can be returned if next key isn't found or even if loop is ended
lastValidValue = current.default;
}
} else {
// curr key is not present, stop iterating for loop
// return last valid
return lastValidValue;
}
}
return lastValidValue;
}
...
// example routes
const root = {
default: "https:/gk.notion.site/default-xxx",
notion: {
default: "https:/gk.notion.site/notion-default-xxx",
"papers": {
default: "https:/gk.notion.site/papers-default-xxx",
"mapreduce": "https:/gk.notion.site/map-reduce-xxx",
},
},
...
}Another interesting approach is to have a big hashmap containing all the individual routes and do lookups for every path segment.
const hashmap = {
"": "",
"notion": "",
"notion/papers": ""
"notion/papers/mapreduce" : ""
}