Notes: https://pdos.csail.mit.edu/6.824/notes/l01.txt
Video: https://youtu.be/WtZ7pcRSkOA
Prep:
-
MapReduce Paper: http://nil.csail.mit.edu/6.5840/2024/papers/mapreduce.pdf
Related Lab
Labs
- MapReduce
- Replication using Raft
- Replicated KV Service
- Sharded KV Service
Focus
Infrastructure
- Storage
- Computation
- Communication
- RPC
Main Topics
- Fault Tolerance
- Availability
- Replication
- Recoverability
- Logging/Transactions
- Durable Storage
- Availability
- Consistency
- Eventual
- Strong
- Peformance
- Throughput
- Latency
- One slow machine slows entire req flow ⇒ tail latency
- Implementation
Trade off b/w them
MapReduce
(for Lab 1)
Paper from Google
It took multiple hours to process TBs of data like web indexing
Approach
- Map + Reduce, functions with sequential code
- Write these functions and handover to programming model (conceptually)
- Programming model will take care of distributing of the process
Abstract View
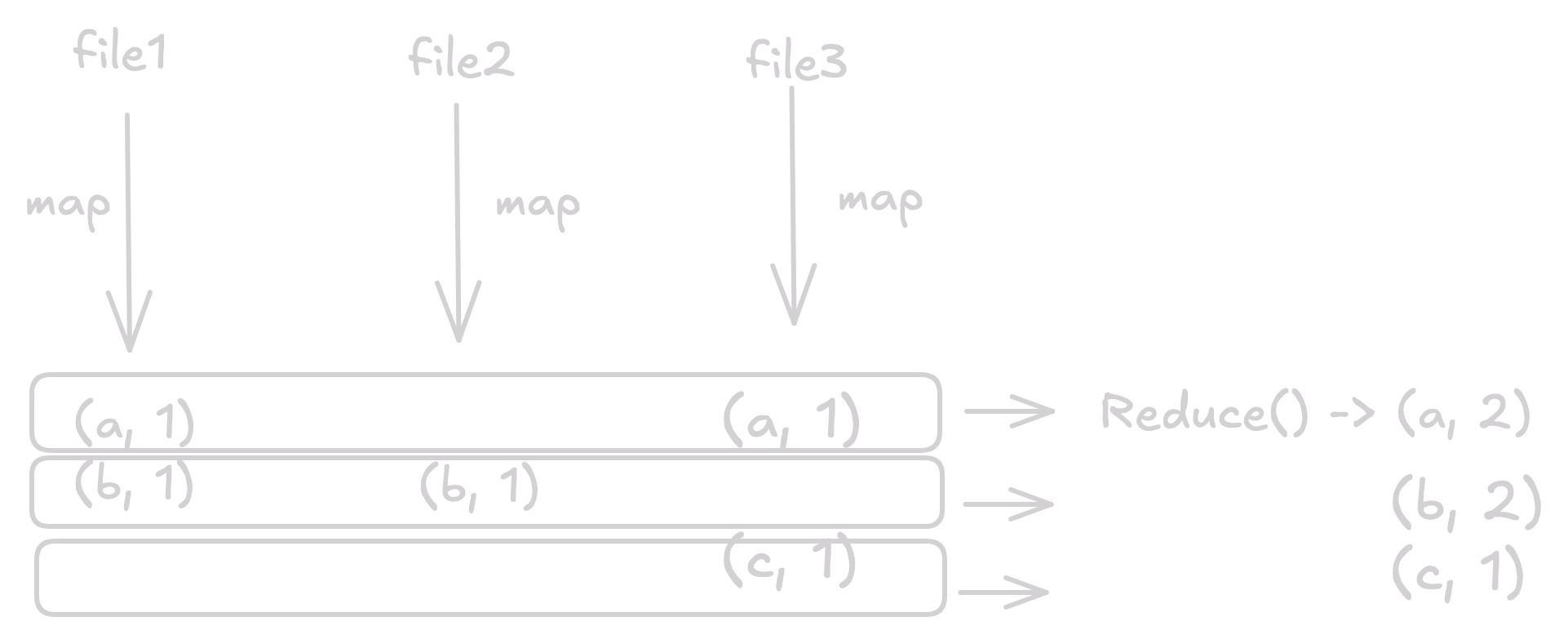
https://excalidraw.com/#json=qEDq6FHf4Zbts_Lni6dkp,p1M8xmgUYUZhPEblnjitMQ
Explanation
files can be of huge size which incur large processing times
map produces kv pairs & is run in parallel, so high throughput + scale
In this example, where files contain words & goal is to compute count of the words.
WordCount, abc represent diff words wrt counter as (k, v) ⇒ (word, count)
Reduce aggregates all values wrt keys as in for “a” word in diagram
Reduce is ran for every row (we have words for every row in our case)
Shuffling process is expensive where reduce function need to get inputs from mapper’s output
then sort by key
Paper Explanation
-
Map
- map(k, v) key is file_name, value is file content (words)
- map emits intermediate values which is (word, “1”)
- emitting is done for every word in file (classic “for” loop), that’s why counter is “1”
-
Reduce
- reduce(k, iterator values) key is specific word, values is list of counts
- function sums all the counts i.e., result++ and then emits result
- so result will will word
-
Sequential code and handles where machines can crash and load imbalances
-
Implementation (main diagram from paper)
- User Program
- It will have MR func
- Submit job here
- this will fork() and schedules processes of master and req. workers
- Master/Coordinator
- handles task, which invoke workers to exec map or reduce func
- Worker
- a Map worker produces intermediate results and writes to local storage/disk
- a Reduce worker retrieves those results and execs reduce func, sort
- After sorting, it’ll output a file
5 splits of data/content is read by 3 map workers, they write to 3 disk locations
2 reduce workers read from 3 disk locations and output 2 final files
We’ll see next about GFS, Google File System, where intermediate results are not stored in local disks
- User Program
Fault Tolerance
Coordinator reruns map/reduce funcs
Even if map is run twice, it’ll output same intermediate values as input is same
Similarly if reduce is run twice, it’ll output same result as intermediate values will be same
So both map and reduce are deterministic
In GFS where intermediate values are not stored in local disk, they do atomic rename, when they had to be re run funcs.
Other Failures
- Coordinator
- Coordinator shouldn’t fail, if failed job should be rerun not just tasks like in MR func
- Authors thought 1 machines running coord is unlikely to go down where 100s running MR tasks
- Slow workers (stragglers)
- when computation is almost done except stragglers, stragglers’ work is offloaded to other workers
- replicating task to reduce tail latency