MapReduce: Simplified Data Processing on Large Clusters
- Introduction
- Programming Model
- Implementation
- Refinements
- Performance, Experience, Related Work, Conclusion
Introduction
MapReduce is a programming model and an associated implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.
Programs can be automatically parallelized and executed on a large cluster of commodity machines.
The problem that this paper tries to solve is to parallelize and distribute workload of diff processes’ raw data or derived data from upstream services. This data is quite large, say in TBs. So authors came up with map and reduce programming inspired from LISP, a functional prog lang.
Programming Model
User has to write Map & Reduce functions
Map func takes (k, v) pair as input and produce/emit intermediate (k, v) pairs
MR (MapReduce) lib will group intermediate (k, v) pairs based on key k, like a list, and sends them to Reduce func
Reduce func takes list (iterator) of intermediate kv pairs, and applies any logic as mentioned by user on values. Iterator as intermediate kv pairs can be very large in number and can’t fit entirely in-mem. On processing, it’ll emit or return output value (mostly zero or one output value).
Simple example of WordCount (counting the number of occurrences of each word in a large collection of documents) with MR
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));map() takes a document file, file name as key and file content as value. It’ll start iterating over content for words, and for every word it emits intermediate (k, v) with k as word w and value as 1.
reduce() takes intermediate kv pairs in form of word as key & iterator as value and sums them up i.e.,result++ and them emits output, which will be word occurences for particular word.
Apart from these 2 funcs, user have to fill MR Spec Obj with names of input, output files and optional tuning params.
This is a super simplified example, more interesting examples include Reverse Web Link Graph, Distributed Sort with Ordering Props.
Implementation
This prog model was mainly targeted on running cluster of 1000s of commodity PCs (non specialized and geenral purpose hardware). Implementation of model can change wrt hardware.
Storage is provided by IDE disks. Storage is actually distributed and managed by GFS, Google File System.
- IDE is like a standard port or interface to attach HDDs, this ATA is succeeded by SATA or Serial Advanced Technology Attachment
Execution Overview
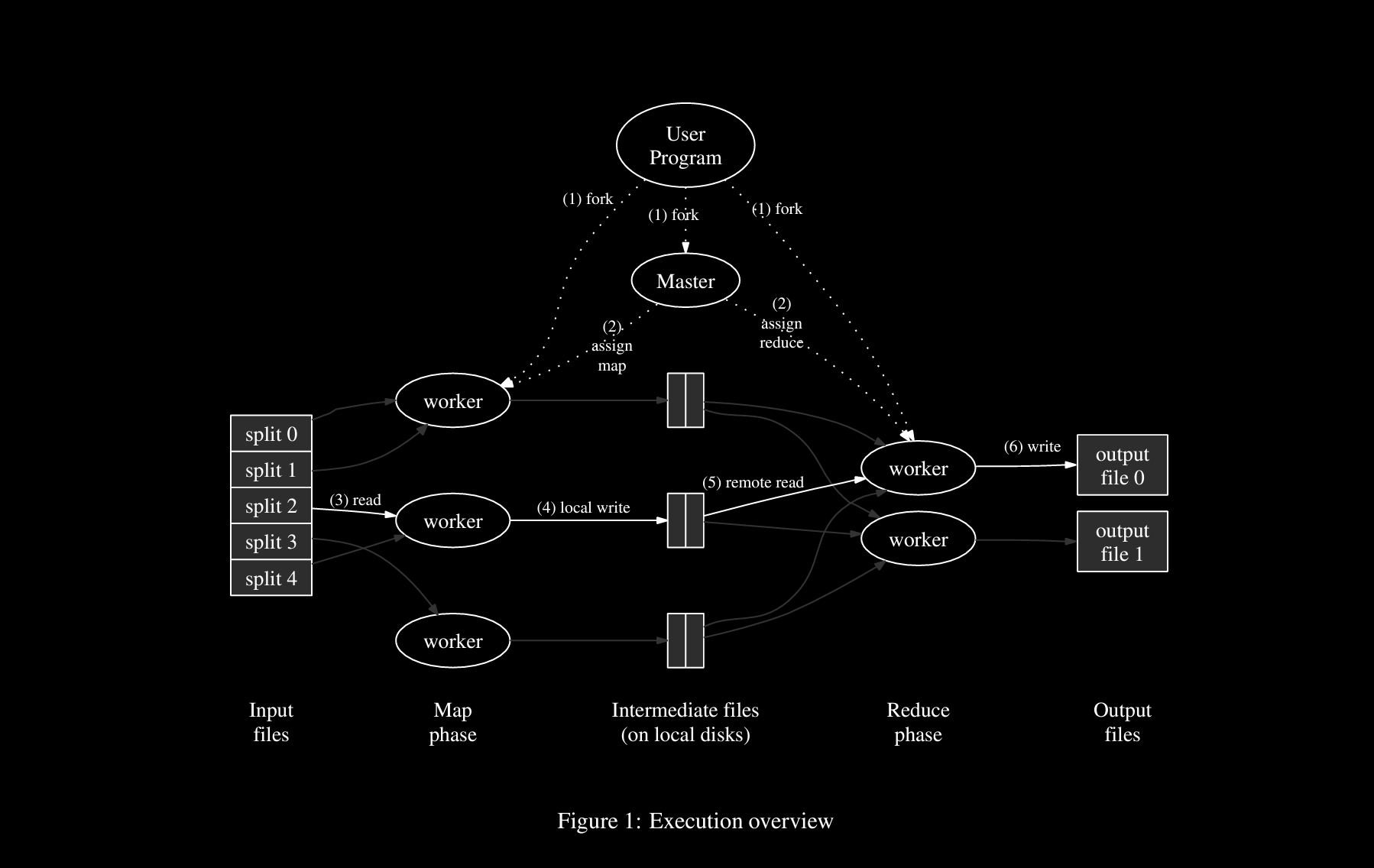
Flow starts at User Program , where MR lib resides, once input file is submitted.
Input data is split into M number of splits (5 in above case). These can be processed in parallel by diff machines.
Also starts to make copies of program on cluster of machines with fork() syscall
One copy as Master and others as worker to run tasks as coordinated by Master where workers might get a map task or reduce task. There can be M map workers & R reduce workers.
Map worker’s work is to read from split(s) then parse kv pairs which should be sent as input for map() i.e., file name and file content like in WordCount.
map() will produce intermediate kv pairs and store in mem buffer then write to local disks. Locations are passed to master
Master then invoked reduce worker. Worker will read intermediate data from disks through RPC remotely.
It’ll also sort data based on key as data is so large and it’ll be easy to search and apply reduce() if values of same keys are adjacent.
Now reduce() is applied and produces final R output files
Master Data Structures & Fault Tolerance
Data structures of Master include state of tasks (idle, in-progress, completed) and id of worker machine running (non-idle) tasks
Master pings workers periodically
- when a worker fails to respond, it’s marked as failed, reset status to
idleand it’s tasks are assigned to another worker
To become fault tolerant, master creates checkpoints. But curr implementation aborts MR process if Master dies.
Atomic commits or renames are done at diff stages. Each in-progress task will write output to private temporary files.
Map task produces R such files (one per reduce task), and a reduce task produces one such file
- Master will receive message with R temp files when map task is completed. It ignores if task is already completed else records temp files
- When a reduce task is done, reduce worker renames temp output file to final output file. If reduce task is completed on diff machine, rename calls still happen. We rely on fs to handle atomic renames which guarantee file consistency that it contains output of only one reduce func.
Mostly MR funcs are deterministic. Atomic renames in the sense,
Locality, Task Granularity, Backup Tasks
Network bandwidth is conserved by taking advantage of GFS. GFS replicates 64 MB of blocks of a file in 3 machines (normally). So whenever a task is executed, input needed for that will be available locally and won’t download from another machine mostly.
For M map & R reduce pieces, M & R should be much larger than workers to get best throughput. Master makes scheduling decisions and keeps state in memory as described above.
They often perform MapReduce computations with M = 200,000and R=5,000,using 2,000 worker machines. M is chose such that input size will be 16 MB to 64 MB
To overcome stragglers, tasks that are lagging to finish and halting completion of entire process, Backup Task Mechanism is deployed. Master schedules backup executions of the remaining in-progress tasks.
Refinements
Partitioning Function & Ordering Guarantees
Default partitioning func which divides/partitions the intermediate data for R workers (see 3 4 5 from execution flow image) is a simple modulo function i.e., hash(key) mod R. It distributes mostly fair resulting in well-balanced partitions but user can also define his own func.
They guarantee that within a given partition, the intermediate key/value pairs are processed in increasing key order. (#check)
Combiner Function, Input & Output Types
Combiner function allows user to partially merge the data before uploading, like articles in document content can be much larger in number, so partially merge them i.e., instead of emitting numerous (”the”, 1), merge them and emit (”the”, 123). But reduce() should be changed accordingly.
Users can add support for a new input type by providing an implementation of a simple reader interface. Each input type implementation should know how to split itself into meaningful ranges for processing as separate map tasks.
Performance, Experience, Related Work, Conclusion
from reference pdf