Notes: https://pdos.csail.mit.edu/6.824/notes/l-gfs.txt
Video: https://youtu.be/6ETFk1-53qU
Prep:
Plan
- Storage Sys
- GFS’ Design
- Consistency
Storage Systems
Building FT storage
App is stateless where storage holds persistent state, makes working with app easy
Why hard to build with FT
high perf ⇒ shard data across servers, because single disk will become bottleneck with throughput
many servers ⇒ constant faults
faults are norm at scale, so need to tolerate
Fault Tolerance ⇒ Replication
Replication ⇒ potential inconsistencies
Strong consistency ⇒ lowers perf as multiple servers make it expensive
Ideal Consistency
Brhaves as if distributed sys as single system
Concurrency
when multiple clients request same resource, it’ll start having conflicts
Overcome using lock
Bad replication plan when there’s no coordination/protocol between servers
returns undesirable results
GFS
Designed for high perofrmnace + replication + FT
successful system
non standard, got bad critique from academia
- only one master
- not consistent, in-consistencies
FS for mapreduce is GFS
at that time, HDDs throughput was 30-40 mbps but mapreduce benchmarks show in order of 1000s (5 to 10) (ofc, many disks are running but still a impressive feat in making them collective). Mapreduce is parallellized so diff disks are utilized
Large data set, whole internet is stored for indexing
fast, auto sharding
global, all apps see same fs
FT, automatic nearly
Design
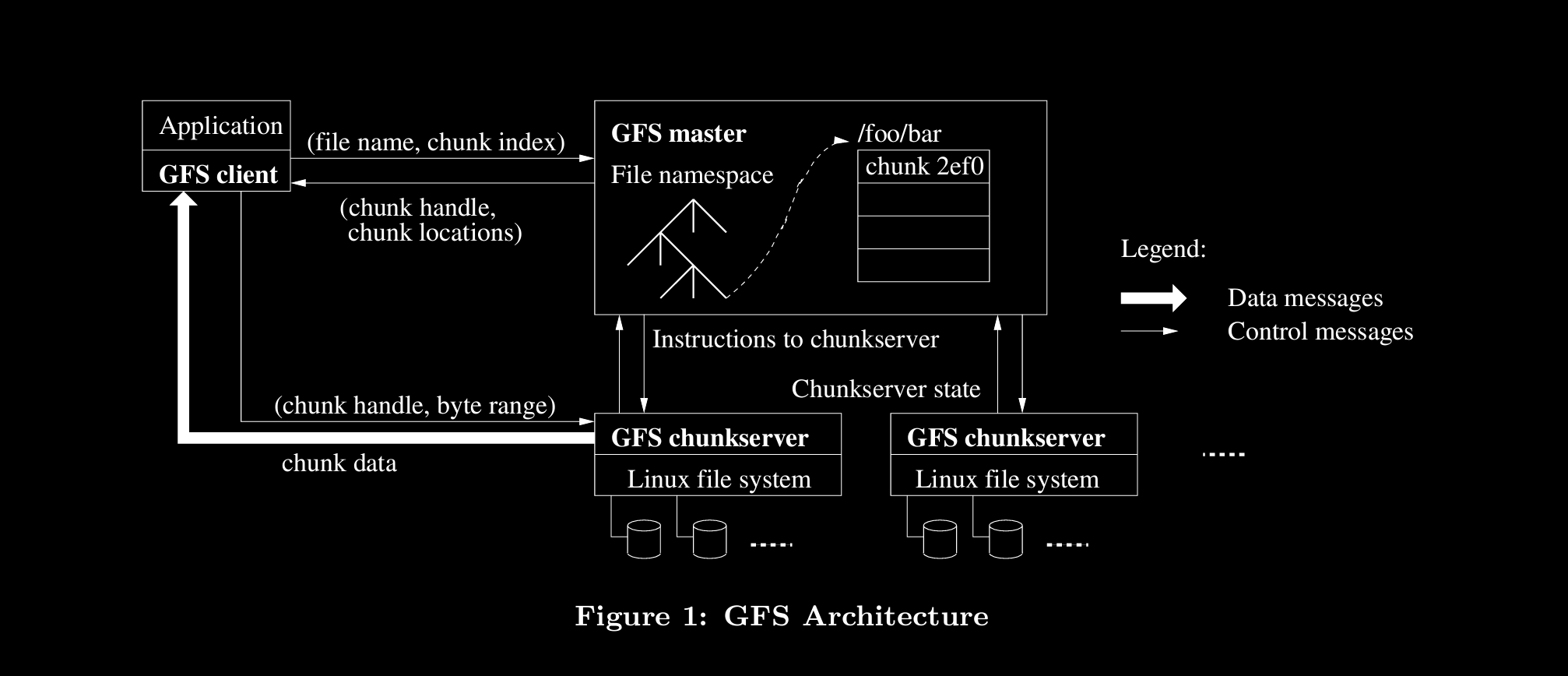
application can be MR
Master is incharge, clients talk with master only
Master talks to chunkservers and return info to clients
clients then directly get chunks from chunkservers (optimized for data flow)
chunk size is 64MB and will be stored in linux fs
Master
it maintains diff things
- filename (stable storage / on disk)
- array of chunk handles
- chunk handle (volatile / memory)
- version# (stable)
- list of chunk servers
- primary, secondary chunk server
- lease time
- oplog + checkpoints
- log is stored on stable storage for good availability and also remotely replicated
- checkpoints are periodically run
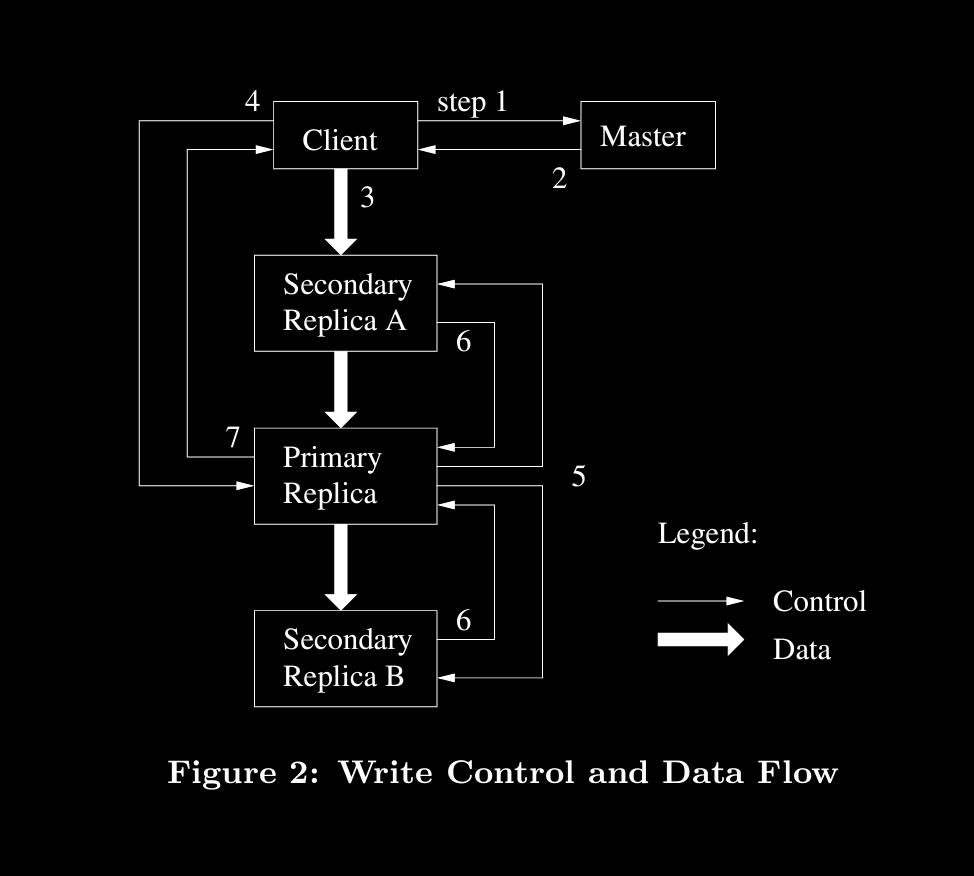
Reading a file
- C asks master wirh offset, filename to know chunkserver
- M → C: chunk handler + list of cks (chunkservers) + v#
- C caches this resp
- C reads from closest cks
- CKS checks v# then sends data
- v# check to find if it’s stale or latest
Writing to file
- Append
- GFS load is mostly append (we can observer this in MR, reduce tasks append computation on computation)
- when master receives append req, before sending avaiable cks
- chunk already has primary and secondary cks or
- chunk doesn’t have them, now master will decide on primary and secondary. Primary will get lease and increments v# of chunk
- v# is stored on disk
- master will send primary + sec + v# to client
- client will have pipeline for high data throughput to cks
- client won’t send data to primary, it will send to closest (can be sec even, sec will then send data to prim) (data flow)
- but client will send req to prim (control flow), so prim can check lease and v#. if not valid, rejects append
- if everything is fine, primary will commit data to chunk and tells sec to commit
- if any sec fails, won;t commit anything. Client should retry
- at-least-once
- a retry will try at diff offset
- if any sec fails, won;t commit anything. Client should retry