The Google File System [GFS]
- Introduction
- Design Overview
- System Interactions
- Master Operation
- Garbage Collection
- Fault Tolerance
- Further
Introduction
The Google File System is a scalable distributed file system for large distributed data-intensive applications. It is designed to run on inexpensive commodity hardware, same as MapReduce.
The largest cluster at that time (i.e., 2003) have over 1000 storage nodes, over 300 TB of disk storage, and are heavily accessed by hundreds of clients on distinct machines.
The main problem GFS focused on, is to meet the rapidly growing demands of Google’s data processing needs. By using inexpensive commodity hardware, it’ll be so easy + scalable.
At the same time, it’s not compromising on typical qualities of previous distributed fs such as performance, scalability, reliability, and availability.
Their findings
- Component failures are common. Commodity hardware adds on this along with software errors. So constant monitoring, error detection, fault tolerance, and automatic recovery are a must.
- Huge files in order of multiple GBs. These files seem like an archive of documents related to webpage. These in total can grow in TBs containing billions of KB-sized files. So I/O & file block sizes are one consideration in designing system.
- Mostly new data is appended to already existed files than over writing old file data. No random writes (so no seeking in HDD), once written, they’re read only (mostly sequential).
- Easy integrations/flexibility b/w app.s and fs api. There’s atomic append operation, so multiple clients append concurrently.
Design Overview
Assumptions
Workloads will have large streaming reads (sequential) & small random reads.
Applications often batch and sort their small reads to advance through the file rather than go back and forth.
Writes are also similar to above Reads
Files are used for producer-consumer queues & many-way merging (K-way_merge_algorithm like tournament tree)
Bandwidth preferred over latency
Interface & Architecture
It’s a very usual FS interface containing op.s like CRUD, open or close file. Then snapshot which will snapshot file/dir at low cost. Record Append which is atomic append.
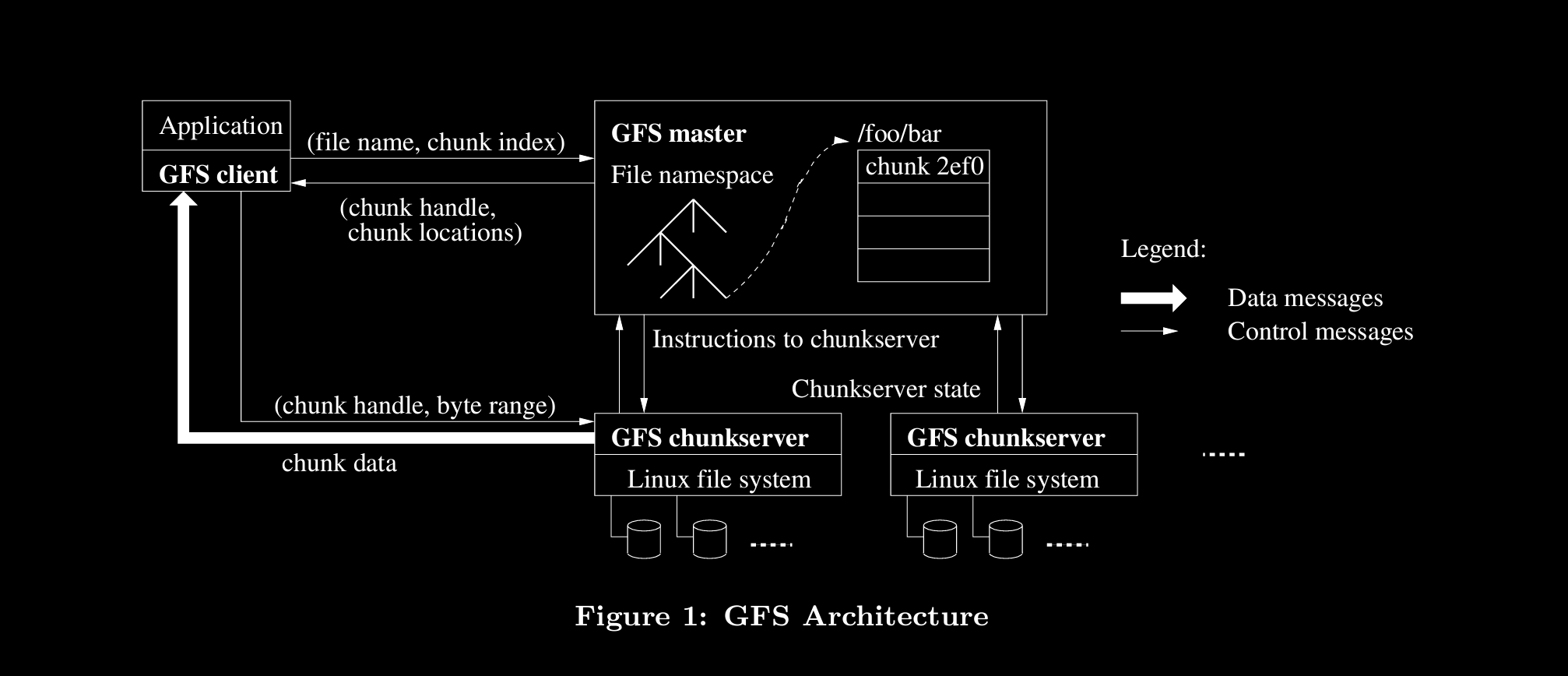
A GFS cluster consists of one master (maintains system metadata) and multiple chunk servers (keeps chunks locally)
Files are divided in fixed-size chunks, where a chunk will have a globally unique immutable 64bit ID called chunk handle
Chunks are replicated (default 3) for reliability
Master controls system-wide activities such as chunk lease management, garbage collection of orphaned chunks, and chunk migration between chunk servers. Also heartbeats chunk servers.
As in figure, client sends request to master and gets metadata of what chunks are needed & in which servers are they located. Client will directly ask chunk servers and gets chunks. Then client can merge all chunks.
Only caching metadata is reasonable but not chunks directly, as they’re are not only large but also never accessed again in cases like streaming.
Chunk caching is handled directly by underlying OS’ FS anyway
Single Master & Chunk Size
Since master doesn’t deliver chunks, but metadata which is magnitudes smaller, a single master is enough for a reasonable scale.
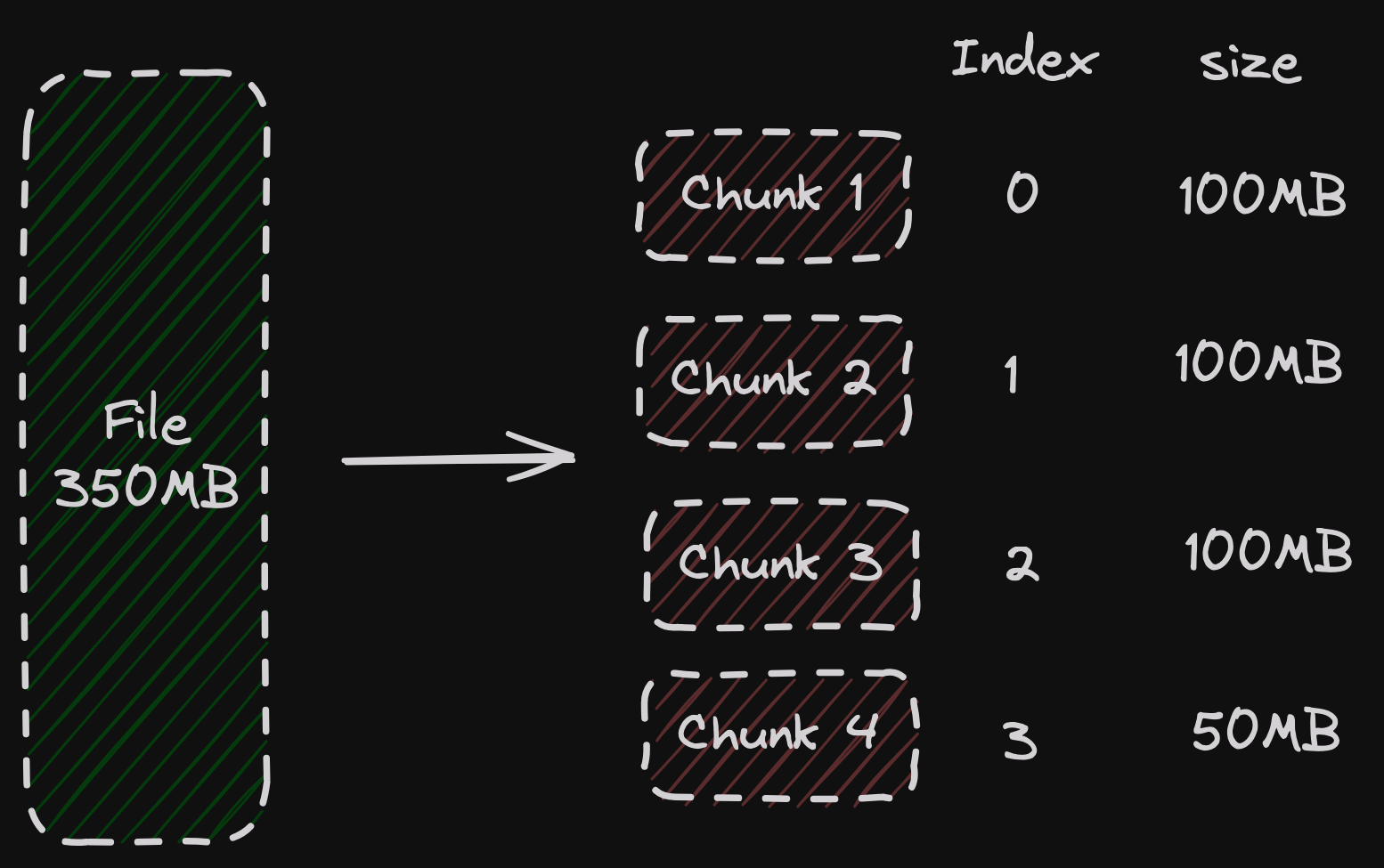
Before sending the request to master, client will calculate chunk index. Since chunk size is fixed, client can calculate and find chunks for a file. Information will be sent from application to client like byte offset.
https://excalidraw.com/#json=1LhDjBTbPwtVQglhjk3rG,9DuKsnVeYVXJb5QBA46h8A
In above example, say client requested a chunk with index 2, master will send Chunk 3’s handle & locations
(Chunk 4 will be padded with extra 50MB for consistent chunk size of 100MB in this example)
Client now will send request to closest location/chunk server for chunk.
These req.s are typically batched to reduce costs.
GFS’ Chunk size is 64MB. Lazy space allocation (allocating space only when asked) avoids wasting space due to internal fragmentation.
When size is large as in 64MB
-
Less interactions with master
-
Sequential operations fit well
-
Client can perform more ops on chunk.
Network overhead is reduced because multiple tcp conns aren’t established & single conn over long time is created until op.s are done
-
Size of metadata stored on master is reduced, so it can be kept in-mem
-
Main disadvantage is chunk servers can become hotspot when many clients request same chunk
Metadata
Master stores 3 types of metadata in memory
- the file and chunk namespaces
- the mapping from files to chunks
- the locations of each chunk’s replicas
1, 2 are persisted on disk in operation log (oplog)
whereas for 3, master will get chunks information by polling chunk servers during startup
In-Memory Data Structures & Chunk Location
Master will periodically scan it’s state in background, which is used for chunk GC, chunk migration to balance load and also replicating chunks when servers go down
So entire system is dependent on size of master’s memory
Persisting chunk locations info at master is a bad idea because chunk servers can change state frequently (join, leave cluster, fail, restart, …)
Operation Log
Serves as a logical time line that defines the order of concurrent operations.
Oplog is replicated to remote machines, master checkpoints ops to oplog
these checkpoints are a btree like structures, so offers faster reads
Oplog is similar to WAL, actually it’s even directly termed in MongoDB as Oplog
Consistency Model
Operations can be writes or record append (atomic append to tackle concurrency). These two are mutations as they change content of chunk.
Op.s in this section are mutations only
File namespace/region is defined after a file mutation if it’s consistent (all clients read same data)
Concurrent successful op.s leave the region undefined but consistent
A failed op makes the region inconsistent , undefined
A write causes data to be written at an a_pplication-specified file offset_.
A record append causes data (the “record”) to be appended atomically at least once even in the presence of concurrent mutations, but at an offset of GFS’s choosing
After a sequence of successful mutations, the mutated file region is guaranteed to be defined and contain the data written by the last mutation. This is achieved by
- applying mutations to a chunk in the same order on all its replicas
- using chunk version numbers to detect staleness
- stale chunks are not involved in any op.s and GC’ed
GFS identifies failed chunk servers by regular handshakes and detects data corruption by check summing
System Interactions
Leases and Mutation Order
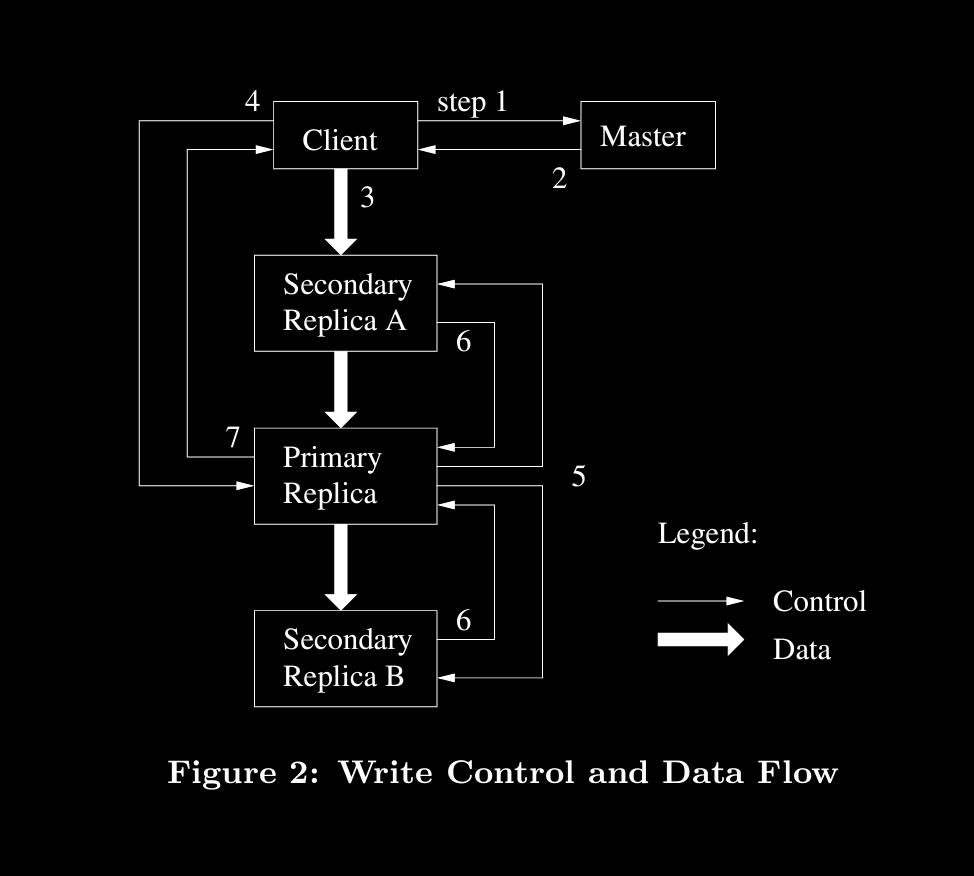
Among the chunk replicas (chunkservers having same chunk), master will elect one primary (if no primary for that chunk) and give it lease of chunk to make mutations.
Primary can extend lease by requesting master during heartbeats. Once all mutations are done (in some serial order), primary will send order to secondaries.
If sec.s apply mutations without any error, mutations are successful, else client have to do again.
Lease mechanism is mainly to make load less on master
Data Flow, Atomic Record Appends, Snapshot
To fully utilize each machine’s network bandwidth, the data is pushed linearly along a chain of chunkservers rather than distributed in some other topology (e.g., tree).
Once pushed, primary will be requested to check for appends that if current record can be fit within the chunk size (64mb). If not, primary will pad and fills 64mb, says the same to secondaries.
Snapshot op will make copy of file/directory very quickly because it uses copy-on-write where a chunk is not created but referenced, and only created when asked to make some op.s
Network topology is created in a way distances b/w servers can be identified by IP addresses
Master Operation
Namespace Management and Locking
the 2 locks
- read lock (shared lock), others can read but can’t write
- write lock (exclusive lock), others can’t read nor write
snapshot as an example
- the directory we’re writing to will have write lock, other processes can’t read or write
- dir that’s getting read will have read lock, other processes can read
Creation, Re-replication, Rebalancing
Chunkreplicas are created for three reasons: chunkcreation, re-replication, and rebalancing.
master chooses chunkservers that server has low disk utilization, and less writing rate
because creating chunks on same machine is costly
master does replication whenever replication number is not met (beginning or servers going down)
rebalancing happens for the same reason like high disk utilization, so chunks need to copied to another and deleted
Garbage Collection
when a file is deleted, it’s just renamed to a name with timestamp and not shown
when master regularly scans these deleted will appear, based on timestamp if more than x days. master will delete
orphaned chunks (not related to any live file) are also removed
By ignoring eager deletion, benefits are accidental deletion recovery
Stale chunks on replicas are detected with version number, which increases with every lease.
During scans, stale chunks are also removed
Fault Tolerance
Chunks are replicated, master also maintains oplog, checkpoints (even updated remotely)
There are also shadow masters that provide read-only access to chunks when master is down
Each chunkserver uses checksumming to detect corruption of stored data
A chunk is broken up into 64 KB blocks. Each has a corresponding 32 bit checksum. Like other metadata, checksums are kept in memory and stored persistently with logging, separate from user data.
For reads, the chunkserver verifies the checksum of data blocks that overlap the read range before returning any data to the requester, whether a client or another chunkserver.
Further
GFS has been replaced by Colossus, with the same overall goals, but improvements in master performance and fault-tolerance. In addition, many applications within Google have switched to more database-like storage systems such as BigTable and Spanner. However, much of the GFS design lives on in HDFS, the storage system for the Hadoop open-source MapReduce.