Notes: https://pdos.csail.mit.edu/6.824/notes/l-memcached.txt
Video: https://youtu.be/eYZg0YJtFEE
Prep:
- Introduction
- Website evolution
- Consistency
- Invalidation of Cache
- Performance Approaches
- More perf clusters (replication)
- Races
- Summary
Introduction
Memcache 2013 by facebook
experience paper
three lessons
impressive perf
tension b/w perf and consistency
cautionary tales
successful
Website evolution
-
typical setup → httpd + web framwork + db
-
as users increase
- run multiple frontends (stateless) connected to same db
-
sharding db (parallelism)
- range based sharding and routing handled with frontend
- comes with own probs. distributed txs, 2pc etc
-
caching, off load the reads from db
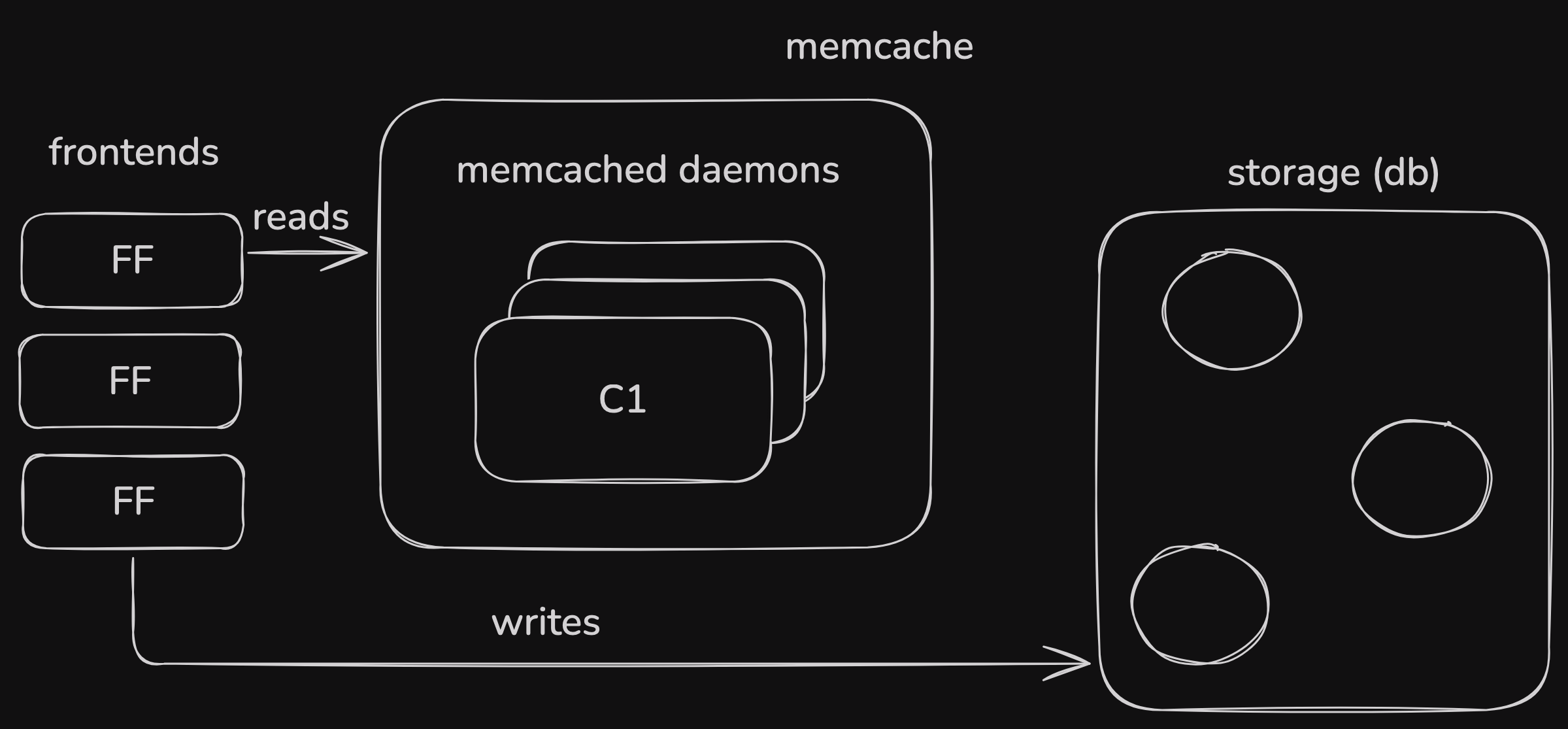
https://excalidraw.com/#json=Ui579v2DD8mxmTLUpDK16,WcwJ2yLKpI1dKmSyClSMlw
challenges
cache to be consistent
avoid db overload
Consistency
eventual consistency
write ordering (database)
reads are behind, acceptable
clients read their own writes
Invalidation of Cache
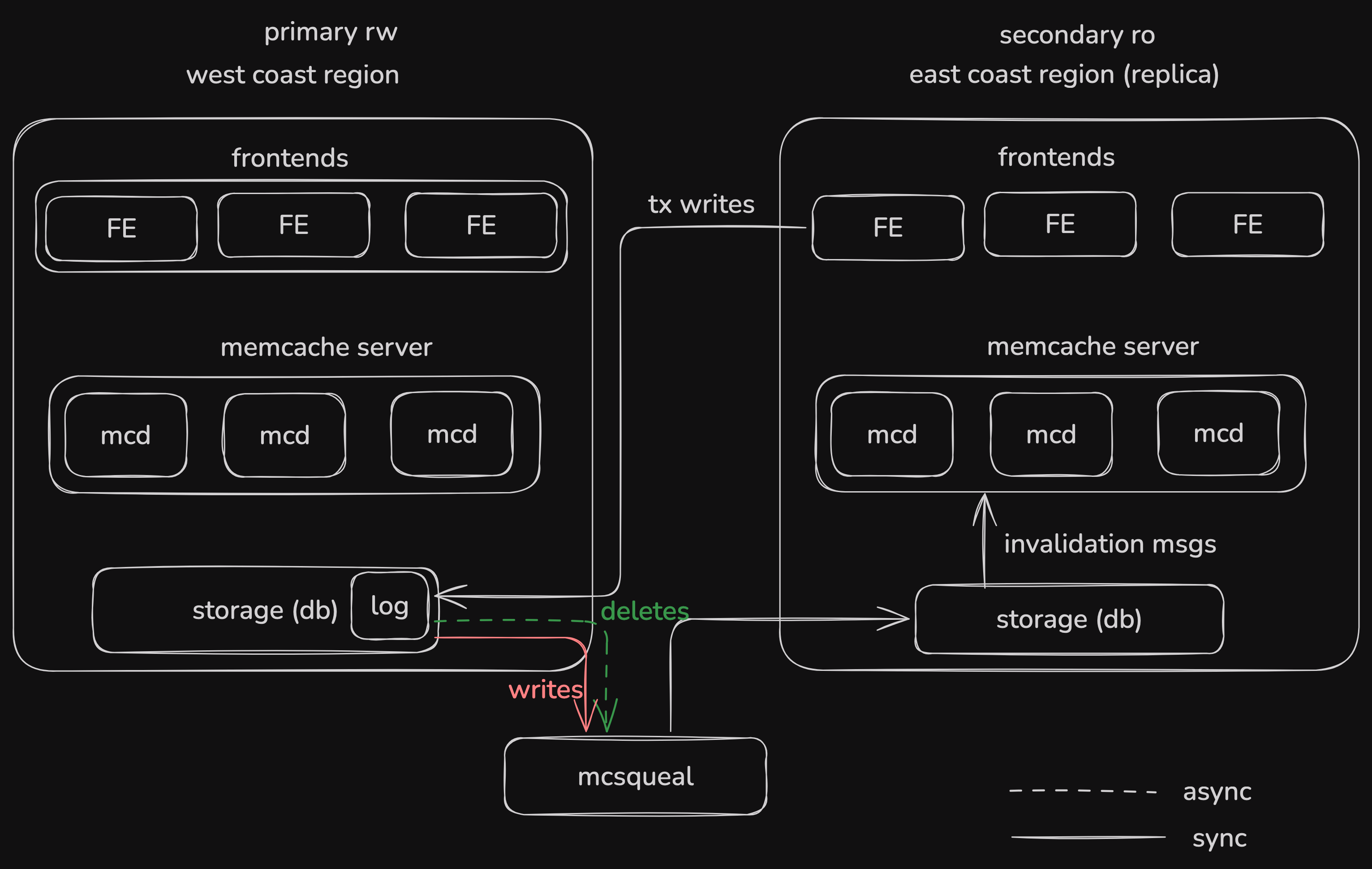
squeal daemons connect with mysql commit log and observe the changes
squeal will send delete req.s to cache based on the commit log
look-aside cache → client queries cache first, then queries db on cache miss
https://excalidraw.com/#json=bIR1Xd4prx_1NkjBwMS1p,bjeOVShjy3PCNRedhcZ9Lw
Performance Approaches
- partition/shard
- +capacity
- +parallel
- replicate
- +hot keys
- -capacity
if mcd instances are increased? every FE talks to every mcd instance ⇒ more tcp conns ⇒ incast congestion
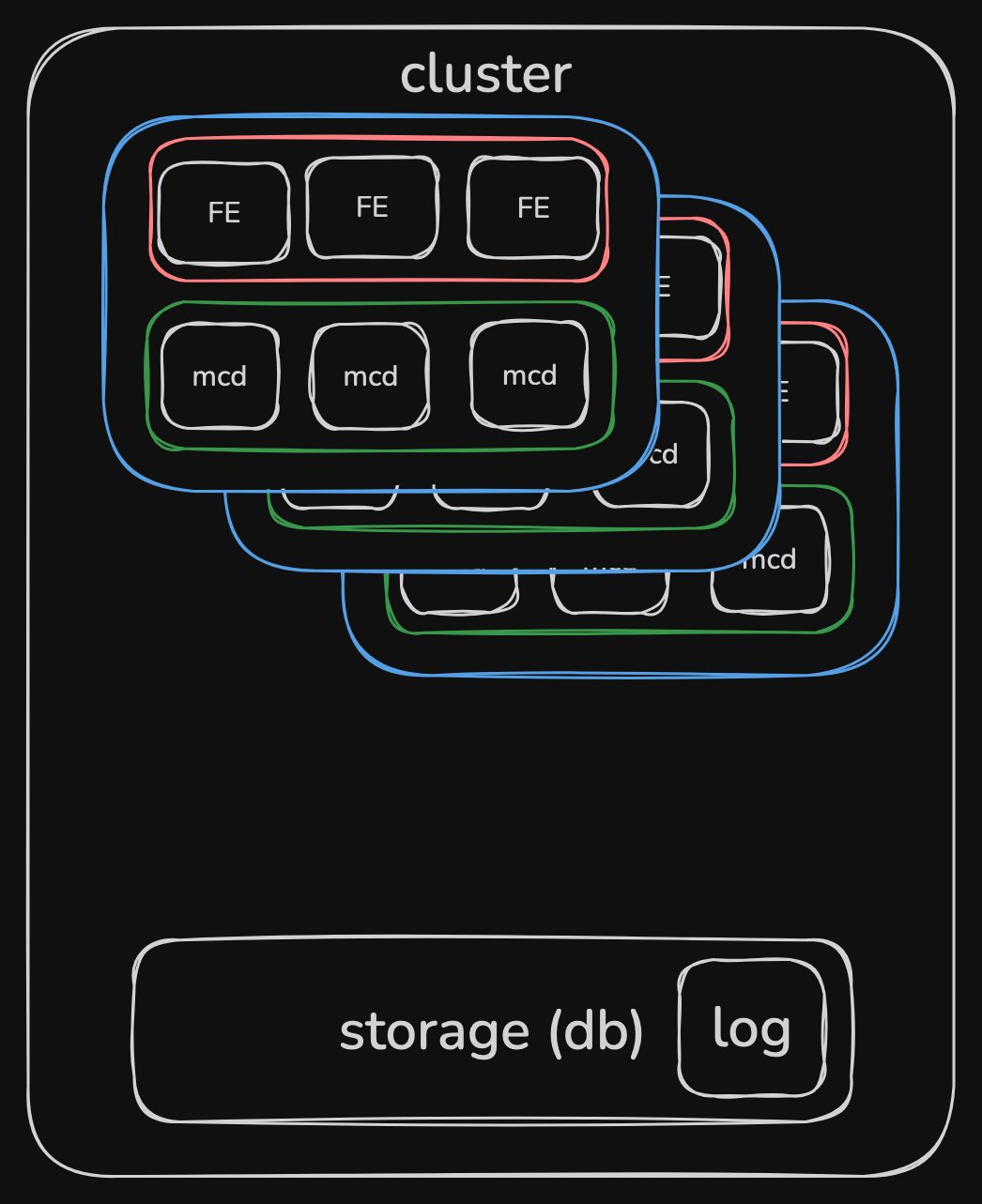
More perf clusters (replication)
replicating FE + mc servers as a cluster in same region
apart from cluster, there’s regional pool which contains less popular keys
when a new cluster starts, it’ll be cold as it won’t contain any cache
so it’ll collect/get cache from old cluster, and warm up/set cold/new cluster
prone to thundering herd if popular key is updated i.e., invalidates cache as reads will directly go to db
if a get op returns nil to client, it’ll have 2 options. One is to get lease, where client have to update that key back again or two, wait for sometime and retry
https://excalidraw.com/#json=zAr0PlfDa79Wema2yTt6j,RBAk4SxuEwm6mFGYHHszxw
mcd server failure i.e., not even returning nil or any resp
this is solved using gutter pool servers
gutter pool will keep cache for only a short period of time
when mc servers fail, client will go to gutter pool and cache is set in gutter pool
small set of machines so invaldations dont happen which will put pressure
Races
Stale Set
solved using same leases, mc server will validate lease that if key can be updated based on previous op
Cold Cluster
a new cluster will be in cold state for few hours until warm up is done
there is a 2 sec hold off when 2 cold clusters try to delete and update a key to avoid race cond
Primary Backup Regions
when a secondary region tries to update data (will go to primary), it’ll trigger cache invalidation
then if it tries to read that key, it’ll get a cache miss ⇒ goes to db, all this happens in primary and squeal will take some time
so inorder to optimize this, remote markers are used where they signify to fetch key from primary region
marker will be removed when it’s safe
Summary
caching is vital
partioning/sharding
replication
consistency b/w db and cache