Scaling Memcache at Facebook
- Pre-Read Thoughts
- Overview
- In a Cluster: Latency and Load
- In a Region: Replication
- Across Regions
- Single Server Improvements
- Memcache Workload
- Post-Read Thoughts
Pre-Read Thoughts
all the time I thought there’s just memcached, a simple in-mem kv store, but the title says memcache
so went on to check and got this SO question which is saying that memcached and memcache are two separate php lib.s (”php” connection makes sense as facebook is written in php
memcached just like etcd, does d ⇒ distributed?
(paper explains this part in the very beginning)
Overview
users consume more than create ⇒ read heavy
Memcached provides ops get, set, delete
analogy in paper is that “memcached” is considered as lib or running binary and ”memcache” to describe distributed system (paper’s title finally makes sense, along with the Scaling Memcache at Facebook)
distributed memcached instances ⇒ memcache
(so d means daemon, and not distributed)
Query Cache: pretty standard way of checking cache before hitting db as in fig
Generic Cache: normal KV store (used for app.s like ML computation vals etc)
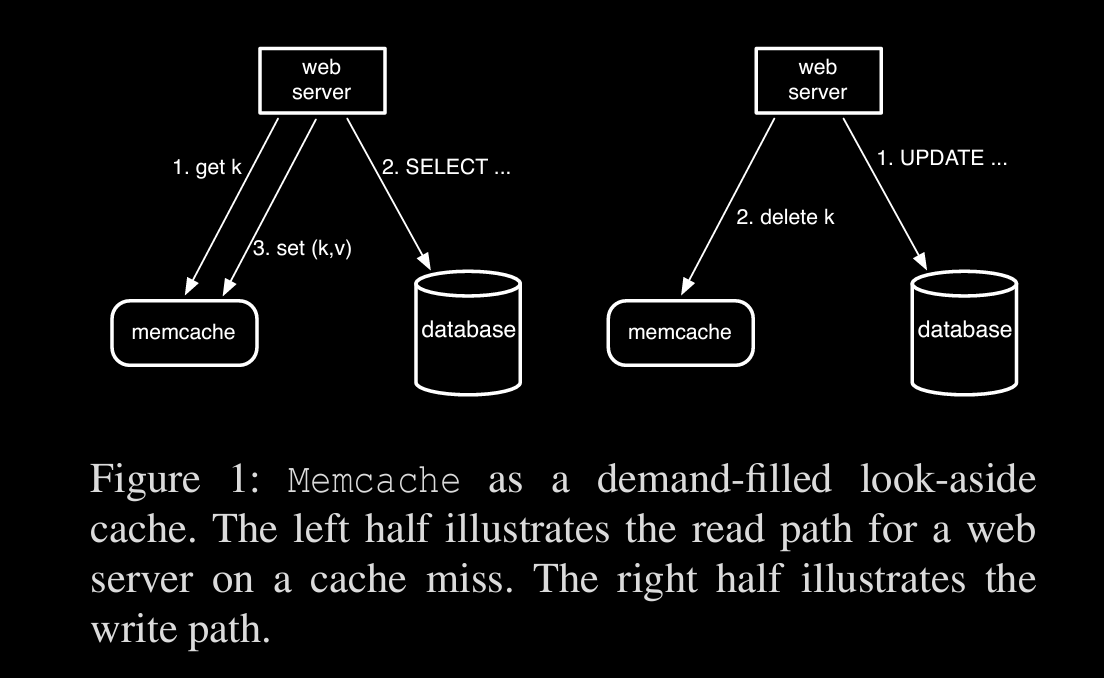
serving stale data for a short period is allowed
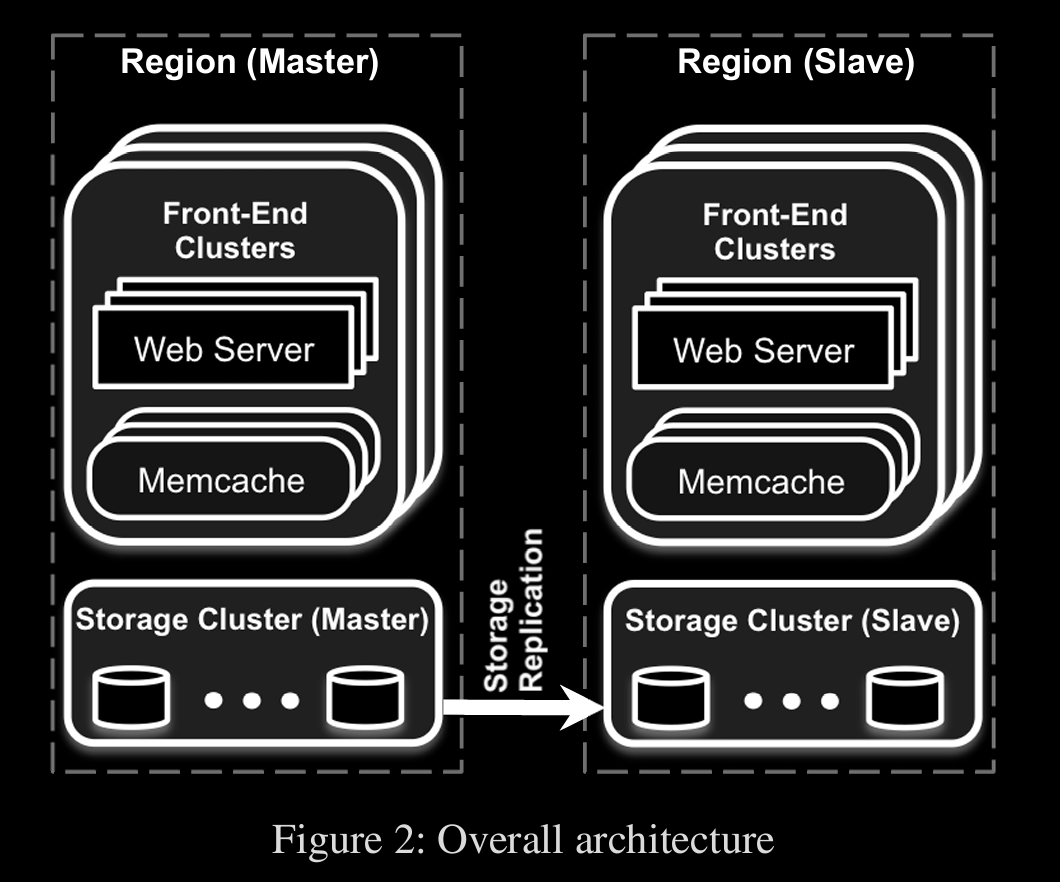
architecture
frontend cluster ⇒ front facing web servers which connect to their own local memcache servers (server running memcached software)
storage cluster is replicated to slave region (only reads are allowed from slaves)
In a Cluster: Latency and Load
cache is distributed in a consistent hashing setup
parallel req.s and batching
data dependency in form of DAG, to get parallelization of related data
client-server communication
udp (less overhead, fast) for gets and tcp for set, updates
these req.s are coalesced/combined at mcrouter
to prevent (incast) congestion, req.s go through sliding window
Leases: for stale sets, thundering herd (related outage in past (2010))
lease is token given to a client during cache read, to put data back in cache incase of cache miss
memcache validates this token, so that if any other req deleted that same key, it won’t proceed
thundering herd is prevented by controlling the token issue rate, so req.s will have to wait
in this gap, results can become stale but that’s fine
Memcache pools
pooling high churn (freq accessed) cache and low churn separately
Handling failures
secondary machines pool called glutter , is maintained to mitigate network partitions accounting to small outages
when a req don’t get any resp, it’ll go to glutter pool
In a Region: Replication
frontend clusters with web + memcache and storage as seen in architecture, define a region
Invalidation
Initially a web server which modifies data sends invalidation req and then there’s mcsqueal, a daemon, which inspects commit log of db and sends invalidation req.s by batching to mcrouter
mcrouter will unpack the batch and delete
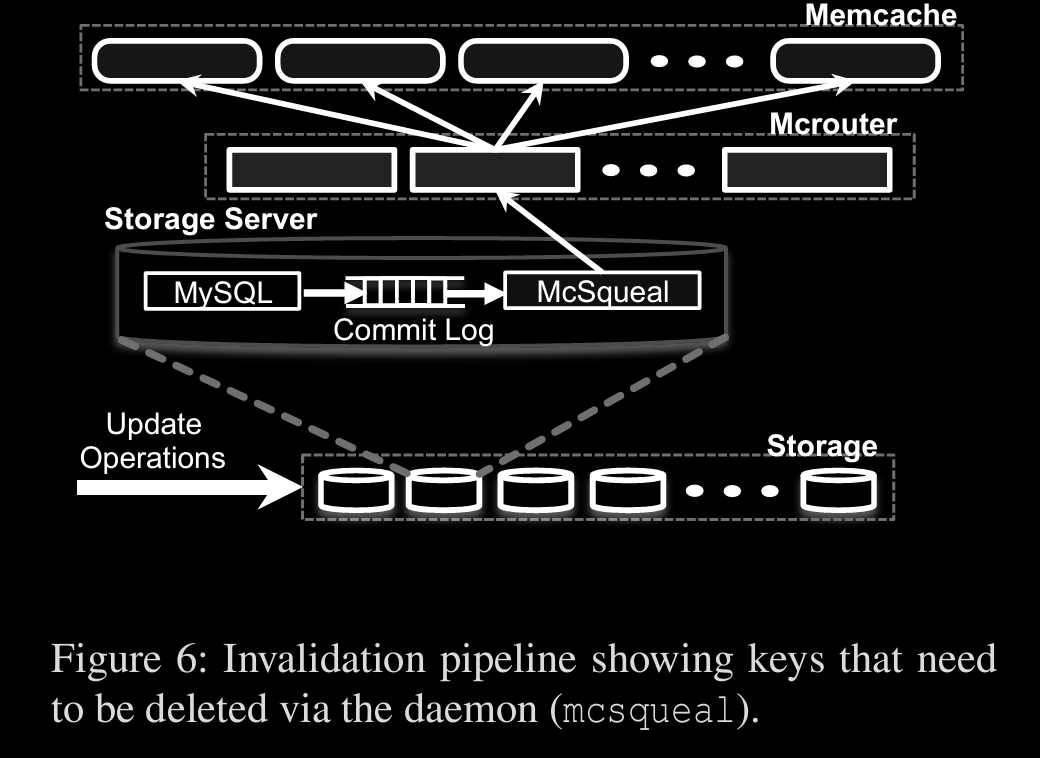
multiple frontend servers share same memcache servers, this is a regional pool
challenge is deciding whether a key needs to be replicated across all frontend clusters or have a single replica per region
when cluster is newly added, it’ll be cold with no cache to server ⇒ more cache misses ⇒ db calls
Cold Cluster Warmup, when cold cluster misses, it’ll go to warm cluster than db
Across Regions
as seen in architecture diagram, master region will have rw access to db, slave regions will have ro
mcsqueal daemons solve race condition, than web servers sending invalidation req.s, as daemons handle only after any txn’s committed and not in between
remote markers are used at slave regions to mark if cache is stale and should be redirected to master
Single Server Improvements
Performance optimizations
diff slab classes are maintained for diff size of cache ⇒ better memory management as no fragmentation
cache is evicted in LRU policy within a slab class
Memcached lazily evicts entries by checking expiration times when serving a get request or at the end of the LRU
short-lived items are places into a circular buffer of linked lists (indexed by seconds until expiration) called the Transient Item Cache, while the others are evicted lazily
Memcache Workload
from reference pdf
Post-Read Thoughts
more of a networking related paper in the beginning than I expected (hence presented at NSDI’13 obviously)
using udp for optimized “gets” seemed interesting as afaik and seen this is not common I think
ik that cache invalidation is one of the two hard problems in CS but caching itself is hard at scale of fb