Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service
- Notation Legend
- Pre-Read Thoughts
- Introduction
- History
- Architecture
- Journey from provisioned to on-demand
- Durability and correctness
- Availability
- Micro benchmarks
- Post-Read Thoughts
- Further Reading
Notation Legend
#something: number ofsomething
→: excerpt from paper
(): an opinion or some information that’s not present in paper
Pre-Read Thoughts
DynamoDB doesn’t need much introduction at this stage, after using and knowing through Dynamo, Cassandra
There are nuances w/ Dynamo, it’s just carrying similar principles.
Dynamo is primarily a Storage system, where as DynamoDB is a Database system, there’s a thin line separating their responsibilities
DynamoDB is also great in the way that, it can fit for most use cases just like PostgreSQL
Introduction
Fundamental properties of DynamoDB
-
consistent performance
-
availability
-
durability
-
a fully managed serverless experience
System Properties
- Multi-tenant architecture
- diff customers but same physical hardware ⇒ cost savings to both parties
- Boundless scale of tables
- no hard limits on data to store on tables
- Highly Available
- replicates at AZ availability Zone level
History
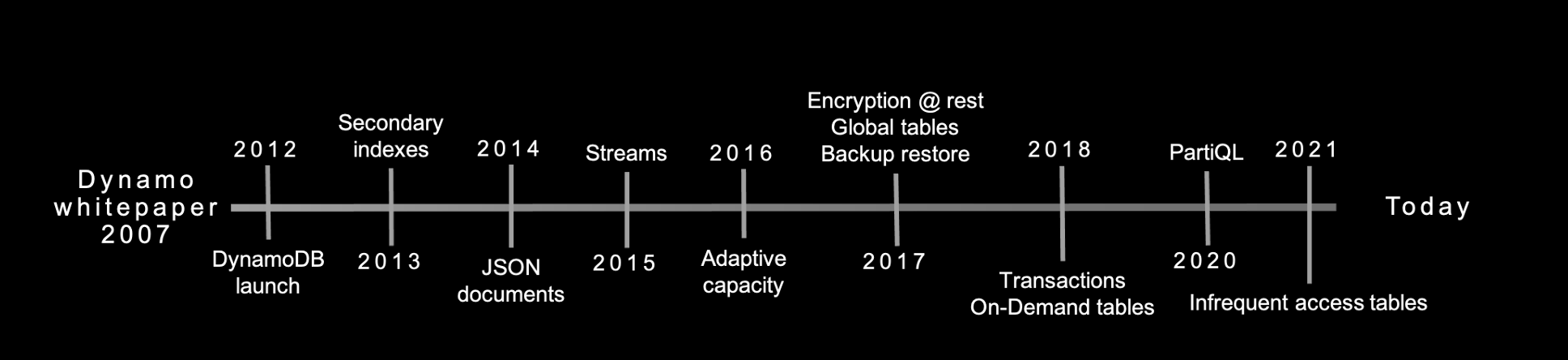
Before DynamoDB, engineers used to have a choice of using Dynamo or SimpleDB
Dynamo is not fully managed, engineers need to manage but is performant
SimpleDB is managed and not performant when compared to Dynamo
→ We concluded that a better solution would combine the best parts of the original Dynamo design (incremental scalability and predictable high performance) with the best parts of SimpleDB (ease of administration of a cloud service, consistency, and a table-based data model that is richer than a pure key-value store).
→ [..] Amazon DynamoDB, a public service launched in 2012 that shared most of the name of the previous Dynamo system but little of its architecture.
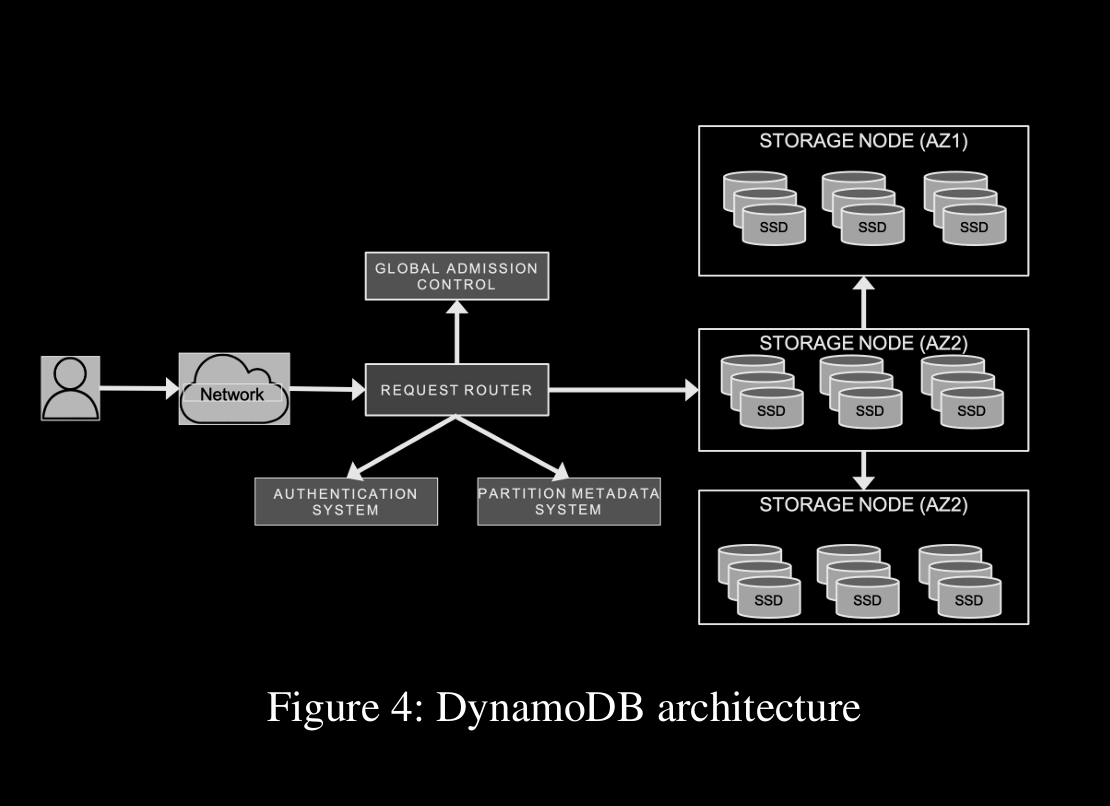
Architecture
→ A DynamoDB table is a collection of items, and each item is a collection of attributes. Each item is uniquely identified by a primary key. The schema of the primary key is specified at the table creation time. The primary key schema contains a partition key or a partition and sort key (a composite primary key).
Supports secondary indexes, ACID transactions
→ The replicas for a partition form a replication group. The replication group uses Multi-Paxos for leader election and consensus.
Writes, strongly consistent reads are served by Leader

Leader updates WAL and sends it other replicas, once quorum is met, write is acknowledged as successful
In case of eventually consistent reads, any of the replica can send response, no need for leader
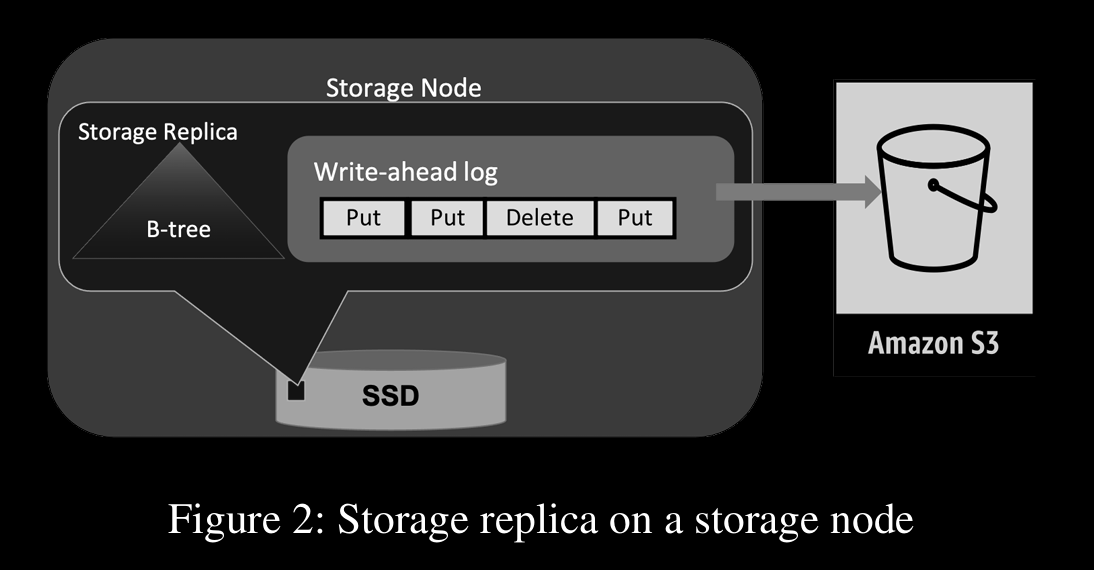
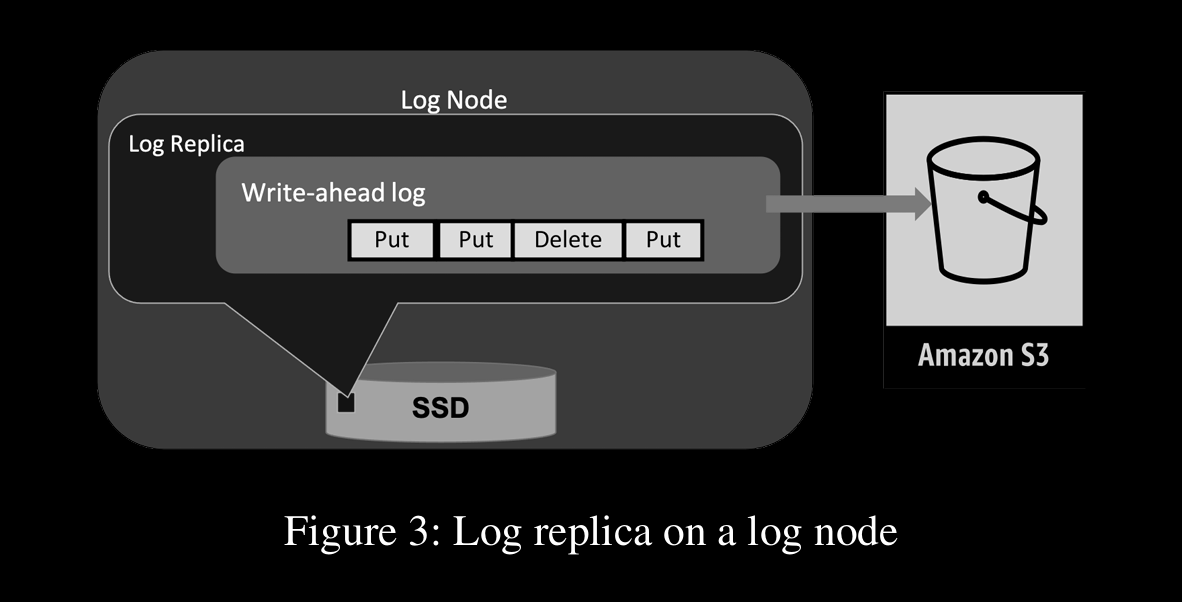
Storage replicas store KV data, indexed as B-Tree and also WAL
Log replicas which only store WAL for HA, durability
→ The metadata service stores routing information about the tables, indexes, and replication groups for keys for a given table or index
→ The request routing service is responsible for authorizing, authenticating, and routing each request to the appropriate server.
→ The autoadmin service [..] is responsible for fleet health, partition health, scaling of tables, and execution of all control plane requests. The service continuously monitors the health of all the partitions and replaces any replicas deemed unhealthy
Journey from provisioned to on-demand
(Provisioned → already setup or reserved capacity ⇒ good for stable traffic)
(On-demand → when needed ⇒ good for traffic spikes)
→ The original system split a table into partitions that allow its contents to be spread across multiple storage nodes
Read or Write Capacity Unit (RCU/WCU)
For items up to 4 KB in size, one capacity unit can perform one strongly consistent read/write request per second.
RCUs + WRUs = provisioned throughssput
→ DynamoDB enforced a cap on the maximum throughput that could be allocated to a single partition
When partitions are made for size, child partitions will have throughput equally divided from parent
When partitions are made for throughput, child partitions will have throughput, not only equally divided but also limited to max throughput a partition should be provisioned to
For example, assume that a partition can accommodate a maximum provisioned throughput of 1000 WCUs. When a table is created with 3200 WCUs, DynamoDB created four partitions that each would be allocated 800 WCUs. If the table’s provisioned throughput was increased to 3600 WCUs, then each partition’s capacity would increase to 900 WCUs. If the table’s provisioned throughput was increased to 6000 WCUs, then the partitions would be split to create eight child partitions, and each partition would be allocated 750 WCUs. If the table’s capacity was decreased to 5000 WCUs, then each partition’s capacity would be decreased to 675 WCUs.
This can lead to hot partition, where keys are not accessed in uniform way as expected by statically partitioning scheme, resulting in rejections of RWs of that partition when it’s hot
throughput dilution happens because on partitioning, throughput of individual partition decreases
Initial improvements to admission control
Bursting
→ The idea behind bursting was to let applications tap into the unused capacity (burst capacity) at a partition level on a best effort basis to absorb short-lived spikes.
Adaptive capacity
→ Adaptive capacity actively monitored the provisioned and consumed capacity of all the tables. If a table experienced throttling and the table level throughput was not exceeded, then it would automatically increase (boost) the allocated throughput of the partitions of the table using a proportional control algorithm.
Global admission control
→ Adaptive capacity was reactive and kicked in only after throttling had been observed. This meant that the application using the table had already experienced brief period of unavailability.
→ The GAC service centrally tracks the total consumption of the table capacity in terms of tokens. When a request from the application arrives, the request router deducts tokens.
→ Eventually, the request router will run out of tokens because of consumption or expiry. When the request router runs of tokens, it requests more tokens from GAC.
now GAC can estimate token consumption and can adapt on token consumption
Balancing consumed capacity
→ Each storage node independently monitors the overall throughput and data size of all its hosted replicas. In case the throughput is beyond a threshold percentage of the maximum capacity of the node, it reports to the autoadmin service a list of candidate partition replicas to move from the current node
Splitting for consumption
→ The split point in the key range is chosen based on key distribution the partition has observed.
→ There are still class of workloads that cannot benefit from split for consumption. For example, a partition receiving high traffic to a single item or a partition where the key range is accessed sequentially will not benefit from split. DynamoDB detects such access patterns and avoids splitting the partition.
On-demand provisioning
→ On-demand tables remove the burden from our customers of figuring out the right provisioning for tables.
→ DynamoDB provisions the on-demand tables based on the consumed capacity by collecting the signal of reads and writes and instantly accommodates up to double the previous peak traffic on the table
Durability and correctness
Hardware failures
→ Write ahead logs are stored in all three replicas of a partition. For higher durability, the write ahead logs are periodically archived to S3
→ Upon detecting an unhealthy storage replica, the leader of a replication group adds a log replica to ensure there is no impact on durability.
Silent data errors
DynamoDB makes extensive use of checksums to detect silent errors. By maintaining checksums within every log entry, message, and log file, DynamoDB validates data integrity for every data transfer between two nodes.
Continuous verification
An example of [..] a continuous verification system is the scrub process.
→ The goal of scrub is to detect errors that we had not anticipated, such as bit rot.
Software bugs
→ The core replication protocol was specified using TLA+
(TLA+ is created by Leslie Lamport, to verify distributed systems and such)
→ When new features that affect the replication protocol are added, they are incorporated into the specification and model checked.
Backups and restores
Backups or restores don’t affect performance or availability of the table as they are built using the write-ahead logs that are archived in S3. The backups are full copies of DynamoDB tables and are stored in an Amazon S3 bucket.
When a point-in-time restore is requested for a table, DynamoDB identifies the closest snapshots to the requested time for all the partitions of the tables, applies the logs up to the timestamp in the restore request, creates a snapshot of the table, and restores it.
Availability
Write and consistent read availability
→ A healthy write quorum in the case of DynamoDB consists of two out of the three replicas from different AZs.
→ If one of the replicas is unresponsive, the leader adds a log replica to the group. Adding a log replica is the fastest way to ensure that the write quorum of the group is always met.
Failure detection
A newly elected leader will have to wait for the expiry of the old leader’s lease before serving any traffic. While this only takes a couple of seconds, the elected leader cannot accept any new writes or consistent read traffic during that period, thus disrupting availability.
To solve the availability problem caused by gray failures, a follower that wants to trigger a failover sends a message to other replicas in the replication group asking if they can communicate with the leader.
Measuring availability & Deployments
DynamoDB handles [.. software] changes with read-write deployments.
The first step is to deploy the software to read the new message format or protocol. Once all the nodes can handle the new message, the software is updated to send new messages.
Dependencies on external services
→ DynamoDB should be able to continue to operate even when the services on which it depends are impaired.
→ In the case of IAM and AWS KMS, DynamoDB employs a statically stable design, where the overall system keeps working even when a dependency becomes impaired.
→ DynamoDB caches result from IAM and AWS KMS in the request routers that perform the authentication of every request.
Metadata availability
The mapping of keys to nodes, is initially stored inside DynamoDB itself
routing information, which is cached (hit rate 99.75%), consists of partitions of table and their key ranges along with storage nodes
By caching, it’s prone to thundering herd and there’s no need for entire partitions’ info for a single req
They built MemDS, an in-mem distributed datastore where it can store all the metadata in memory and replicate it across the MemDS fleet.
The MemDS process on a node encapsulates a Perkle data structure, a hybrid of a Patricia tree and a Merkle tree.
→ In the new cache, a cache hit also results in an asynchronous call to MemDS to refresh the cache.
Micro benchmarks
from reference pdf
Post-Read Thoughts
“Journey from provisioned to on-demand” is most interesting part of this paper
Statically Stable Design, mentioned in Availability’s 6.5, is also interesting
Further Reading
https://www.allthingsdistributed.com/2012/01/amazon-dynamodb.html
https://aws.amazon.com/builders-library/static-stability-using-availability-zones/