Cassandra - A Decentralized Structured Storage System
- Notation Legend
- Pre-Read Thoughts
- Introduction
- Related Work
- Data Model
- API
- System Architecture
- Practical Experiences
- Post-Read Thoughts
- Further Reading
Notation Legend
#something: number ofsomething
→: excerpt from paper
(): an opinion or some information that’s not present in paper
Pre-Read Thoughts
Cassandra or C* (C STAR) or (my preference) Cass, is a wide-column CAP database aimed at higher write-throughput using LSM Trees
Avinash Lakshman, who worked on Dynamo- Amazon’s Highly Available Key-value Store, is co-author of Cassandra. One of the reasons for Cass being similar to Dynamo design.
Started at Facebook and later handed over to Apache Software Foundation as part of open-sourcing
Was working with Cassandra recently and I should mention, it’s quite a heavy app (usual suspects JVM & GC)
ScyllaDB , for which Discord moved from Cassandra, is drop-in replacement for it, which is written in C++, using latest algorithms like Raft
Introduction
Designed for Inbox Search feature at Facebook
Requirement is to handle 1B writes a day
Related Work
→ Dynamo allows read and write operations to continue even during network partitions and resolves update conflicts using different conflict resolution mechanisms, some client driven
Traditional RDBMS is limited to scale and also availability
→ Dynamo detects updated conflicts using a vector clock scheme, but prefers a client side conflict resolution mechanism
→ Bigtable provides both structure and data distribution but relies on a distributed file system for its durability.
Data Model
→ Every operation under a single row key is atomic per replica no matter how many columns are being read or written into.
→ Cassandra exposes two kinds of columns families, Simple and Super column families. Super column families can be visualized as a column family within a column family.
Columns are sorted by time or name
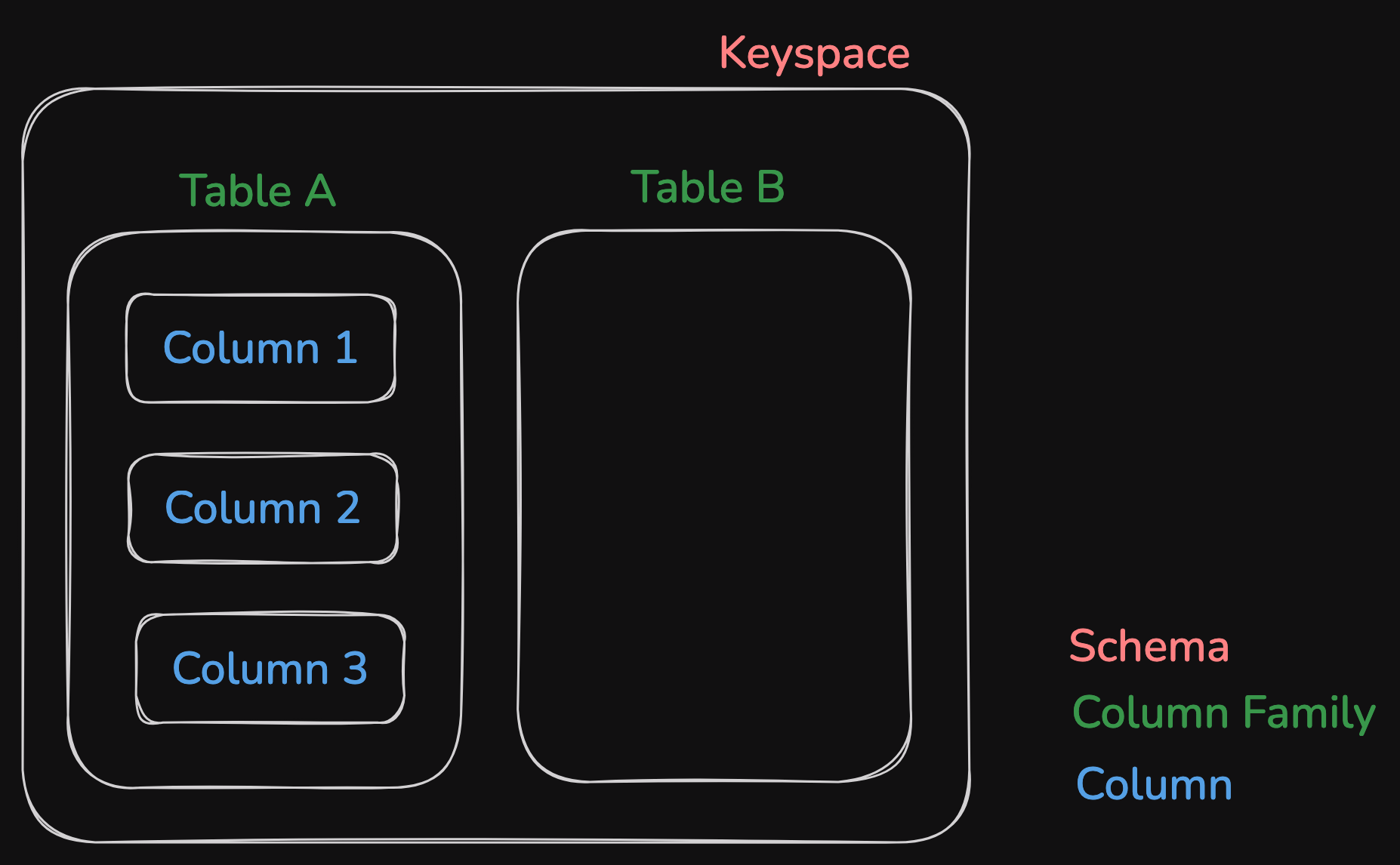
https://excalidraw.com/#json=drdyNYchh-X8hY25Em9Tw,7FguAYUcn7sMmbMkarl0Zg
API
- insert(
table,key,rowMutation) - get(
table,key,columnName) - delete(
table,key,columnName)
→ columnName can refer to a specific column within a column family, a column family, a super column family, or a column within a super column
table, key, columnName ⇒ KKV (Key Key Value) structure like in Dynamo
System Architecture
→ Characteristics : scalable and robust solutions for load balancing, membership and failure detection, failure recovery, replica synchronization, overload handling, state transfer, concurrency and job scheduling, request marshalling, request routing, system monitoring and alarming, and configuration management.
a read or write request can go to any available node, that node will route the request to a replica that holds that key
for writes, quorum much be achieved among replica set
for reads, based on consistency guarantee required by client, either it will get from nearest replica or ask all replicas
Partitioning
to scale, data is to be partitioned dynamically, this is where consistent hashing comes
with “consistent” hashing, the members of the ring stay consistent, only neighbors are effected
partition in cass happens (i.e., movement nodes from one place to another in ring) happens based on load capacity (lightly loaded nodes will move towards heavily loading nodes to balance)
this is opp of what happens in Dynamo, where one node takes multiple positions
Replication
Let N be the replication factor, coordinator will replicate the key that it’s incharge of to N-1 successor nodes. This is Rack Unaware replication policy
Policies
- Rack Unaware
- Rack Aware
- Datacenter Aware
For Aware policies, zookeeper is used for leader node election. It’s responsibility is to tell nodes what keys they should be replicating or keeping with them.
ZK will maintain a list of which nodes are responsible for their respective range of keys, with this any node can know about any other node and it’s range of keys responsible for
Membership
Based on Scuttlebutt, which translates to Gossip protocol
Failure Detection
Node faliures are detected using (Phi) Accrual Failure Detector
In this detection model, a suspicion level phi is given, instead of a boolean for node’s status
(nodes will gossip through heartbeats)
here when phi = x, it means that node is considered down if x heartbeats are missed from it
Bootstrapping
→ When a node starts for the first time, it chooses a random token for its position in the ring
→ In the bootstrap case, when a node needs to join a cluster, it reads its configuration file which contains a list of a few contact points within the cluster. We call these initial contact points, seeds of the cluster. Seeds can also come from a configuration service like Zookeeper.
Scaling the Cluster
balancing heavily loaded node with lightly node
→ The node giving up the data streams the data over to the new node using kernel-to-kernel copy techniques.
Local Persistence
→Typical write operation involves a write into a commit log for durability and recoverability and an update into an in-memory data structure.
first write into commit log then in-memory data structure (memtable), which gets compacted into disk upon reaching certain threshold
→ All writes are sequential to disk and also generate an index for e cient lookup based on row key.
→ In order to prevent lookups into fles that do not contain the key, a bloom filter, summarizing the keys in the file, is also stored in each data file and also kept in memory.
Implementation Details
The Cassandra process on a single machine is primarily consists of the following abstractions: partitioning module, the cluster membership and failure detection module and the storage engine module
→ when read/write request arrives at any node in the cluster the state machine morphs through the following states (i) identify the node(s) that own the data for the key (ii) route the requests to the nodes and wait on the responses to arrive (iii) if the replies do not arrive within a con gured timeout value fail the request and return to the client (iv) gure out the latest response based on timestamp (v) schedule a repair of the data at any replica if they do not have the latest piece of data.
→ Cassandra morphs all writes to disk into sequential writes thus maximizing disk write throughput.
→A typical read operation always looks up data first in the in-memory data structure. If found the data is returned to the application since the in-memory data structure contains the latest data for any key. If not found then we perform disk I/O against all the data files on disk in reverse time order.
Practical Experiences
from reference pdf
Post-Read Thoughts
very light paper, Phi accrual failure detection is interesting
Good number of inspirations are present in Cassandra from Bigtable, where Google termed infamous “memtable”
Further Reading
Dynamo- Amazon’s Highly Available Key-value Store
Amazon DynamoDB- A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service