Kafka: a Distributed Messaging System for Log Processing
- Notation Legend
- Pre-Read Thoughts
- Introduction
- Related Work
- Kafka Architecture and Design Principles
- Kafka Usage at LinkedIn & Experimental Results
- Post-Read Thoughts
- Further Reading
Notation Legend
#something: number ofsomething
→: excerpt from paper
(): an opinion or some information that’s not present in paper
Pre-Read Thoughts
Kafka is pretty hyped-up tool for it’s throughput, at least for me (way before I know distributed systems and all)
I know most high level APIs (as I worked with them) and some internals because of it’s popularity, so focusing more on Message Delivery Semantics if there’s any
To be noted that in current version, Zookeeper’s role (as coordinator) is deprecated and replaced with KRaft which is based on Raft (raft is taking on everything where there’s consensus!)
Introduction
Kafka is a distributed messaging system for collecting and delivering high volumes of log data with low latency
Log data ⇒ user activity (clicks, likes), operational & system metrics (latency, h/w)
Related Work
Kafka is different from traditional messaging sys.s
They’re offering features which degrades throughput like atomically delivering msgs and delivery acks, and hard to distribute
Kafka is pull based and not push based
Kafka Architecture and Design Principles
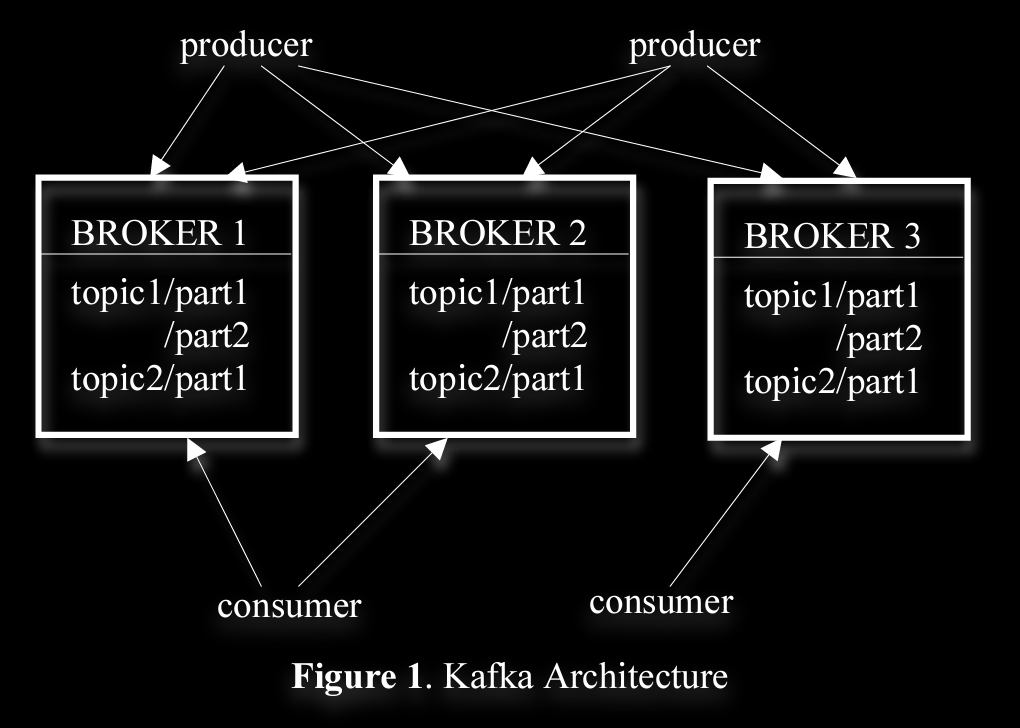
A stream of messages of a particular type is defined by a topic. A producer can publish messages to a topic. The published messages are then stored at a set of servers called brokers. A consumer can subscribe to one or more topics from the brokers, and consume the subscribed messages by pulling data from the brokers.
consumer simply creates a msg stream iterator which doesn’t end on a topic
topic can have multiple partitions in multiple brokers
Efficiency on a Single Partition
Simple Storage

each partition corresponds to a log which is set of segment files
for better perf, they batch messages and flush segment files, only then consumed
each msg can be ID’ed by offset
consumer consumes sequentially
broker keeps in-mem idx as shown in left with first message offset/id of segment file
Efficient Transfer
there is no explicit caching made by Kafka Broker, it just relies on OS to cache as page cache
it also helps when broker restarts since cache is at OS level and not app level
to send messages to consumers, it uses sendfile sys call which is efficient by directly sending file at socket level with no hops with application
Stateless Broker
broker doesn’t maintain any record of messages consumed by consumers
msgs have retention policy of 7 days (configurable), so msgs can be replayed incase of consumer app crash or some other event
Distributed Coordination
a producer can publish to partition randomly or by partition key or function
consumers are grouped under consumer group , where msgs consumed under this group are consumed by only one of the consumer
Kafka uses Zookeeper for the following tasks
- detecting the addition and the removal of brokers and consumers
- triggering a rebalance process in each consumer when the above events happen
- maintaining the consumption relationship and keeping track of the consumed offset of each partition.
The broker registry contains the broker’s host name and port, and the set of topics and partitions stored on it.
The consumer registry includes the consumer group to which a consumer belongs and the set of topics that it subscribes to.
Delivery Guarantees
at-least-once delivery is guaranteed, exactly-once requires 2PC and not effective for their use-case
But it’s suggested to handle de-duplication logic from application side
messages from single partition will always be delivered in order, no guarantee from other partitions
to check corruption in messages, CRC is used
Kafka Usage at LinkedIn & Experimental Results
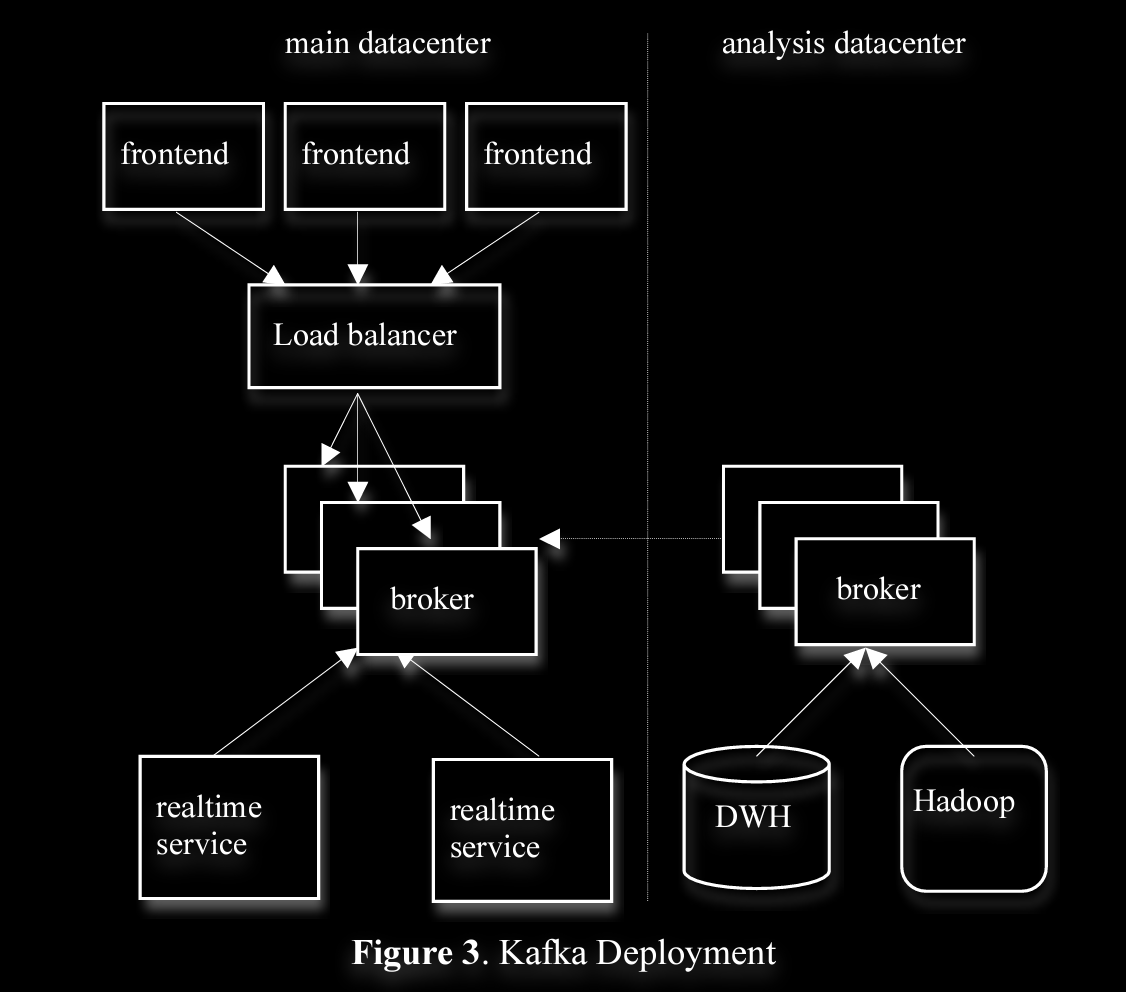
from reference pdf
Post-Read Thoughts
Paper being very light, main content tend to be Kafka’s architecture & design principles with distributed coordination and delivery guarantees
I just realized that Kafka- a Distributed Messaging System for Log Processing is exactly what I heard 2 years back in ByteByteGo’s Why is Kafka Fast?
Current features which are interesting are future works to that time of writing
- Message replication
- Dead letter queue