Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
- Notation Legend
- Pre-Read Thoughts
- Introduction
- Resilient Distributed Datasets (RDDs)
- Spark Programming Interface
- Representing RDDs
- Implementation
- Post-Read Thoughts
- Further Reading
Notation Legend
#something: number ofsomething
→: excerpt from paper
(): an opinion or some information that’s not present in paper
Pre-Read Thoughts
(Continuing after Spark- Cluster Computing with Working Sets)
with previous read, got to know about RDDs which are powering blocks for Spark
RDDs API is not used much now tho. DataFrames API is used w/ PySpark
Introduction
Current data processing frameworks are inefficient at applications which are iterative in nature like ML jobs, due to the lack of good distributed memory abstraction like RDD.
Another application is large scale data mining, which comes with great cost in terms of various IO ops
→ RDDs are fault-tolerant, parallel data structures that let users explicitly persist intermediate results in memory, control their partitioning to optimize data placement, and manipulate them using a rich set of operators.
Lineage : RDDs are replicated per se, so when an partition is lost, it is recompute. It’s way more efficient than maintaining replicas in this case.
Resilient Distributed Datasets (RDDs)
→ an RDD is a read-only, partitioned collection of records. RDDs can only be created through deterministic operations (or transformations) on either (1) data in stable storage or (2) other RDDs
→ users can control two other aspects of RDDs: persistence and partitioning.
RDD is created initially by taking some data from storage and then transformations are applied. Transformations can be map, filter, join. Actions can be performed once created like
count(which returns the number of elements in the dataset)collect(which returns the elements themselves)save(which outputs the dataset to a storage system)
Example
simplified example of searching errors in terabyte sized logs (log mining)
→ Line 1 defines an RDD backed by an HDFS file (as a collection of lines of text), while line 2 derives a filtered RDD from it. Line 3 then asks for errors to persist in memory so that it can be shared across queries.
lines = spark.textFile("hdfs://...") // not stored in-mem, can be large enough
errors = lines.filter(_.startsWith("ERROR"))
errors.persist()
errors.count()
// Count errors mentioning MySQL:
errors.filter(_.contains("MySQL")).count()
// Return the time fields of errors mentioning
// HDFS as an array (assuming time is field
// number 3 in a tab-separated format):
errors.filter(_.contains("HDFS")).map(_.split(\t)(3)).collect()→ In this query, we started with errors, the result of a filter on lines, and applied a further filter and map before running a collect. The Spark scheduler will pipeline the latter two transformations and send a set of tasks to compute them to the nodes holding the cached partitions of errors. In addition, if a partition of errors is lost, Spark rebuilds it by applying a filter on only the corresponding partition of lines.

Advantages of RDD Model
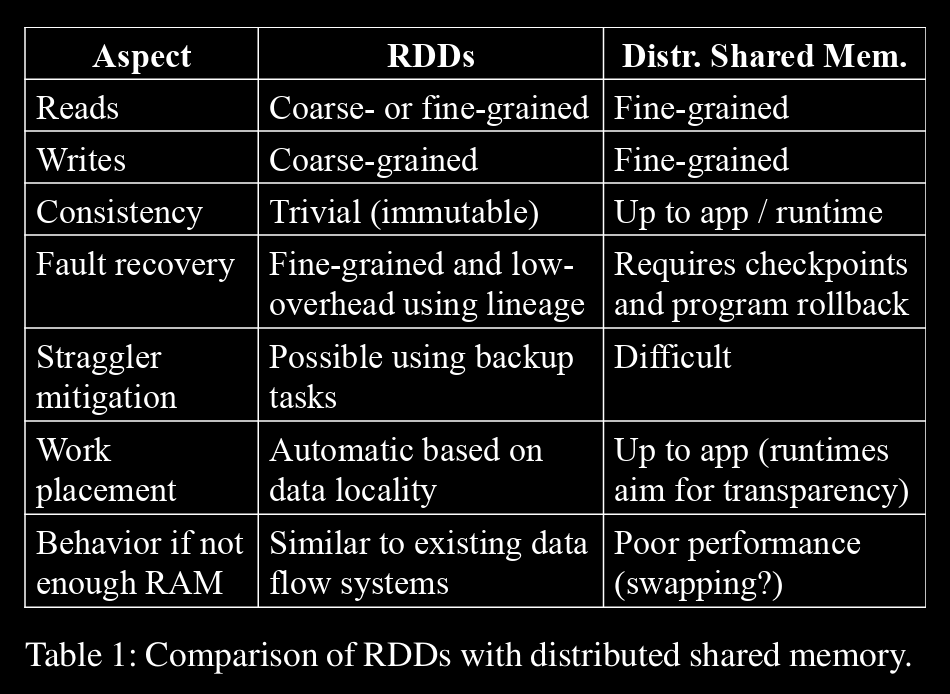
RDDs vs DSM/Distributed Shared Memory
→ DSM is a very general abstraction, but this generality makes it harder to implement in an efficient and fault tolerant manner on commodity clusters.
→ The main difference between RDDs and DSM is that RDDs can only be created (“written”) through coarsegrained transformations, while DSM allows reads and writes to each memory location.
→ Second benefit of RDDs is that their immutable nature lets a system mitigate slow nodes (stragglers) by running backup copies of slow tasks as in MapReduce
Spark Programming Interface
→ We chose Scala due to its combination of conciseness (which is convenient for interactive use) and efficiency (due to static typing).
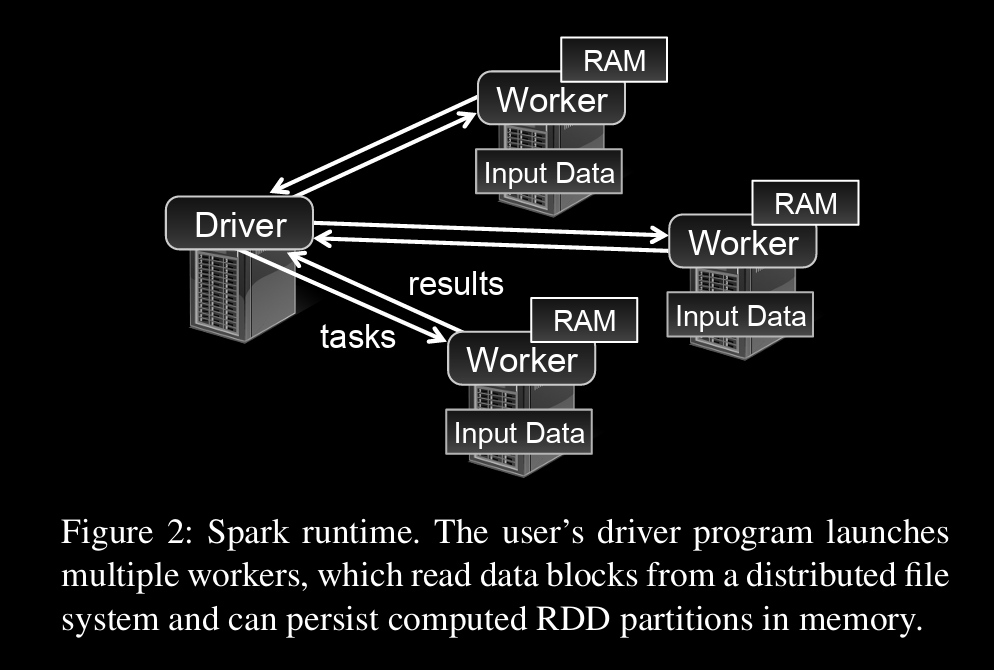
→ To use Spark, developers write a driver program that connects to a cluster of workers.
→ The driver defines one or more RDDs and invokes actions on them.
→ users provide arguments to RDD operations like map by passing closures (function literals).
→ Scala represents each closure as a Java object, and these objects can be serialized and loaded on another node to pass the closure across the network. Scala also saves any variables bound in the closure as fields in the Java object.
→ transformations are lazy operations that define a new RDD, while actions launch a computation to return a value to the program or write data to external storage.
Representing RDDs
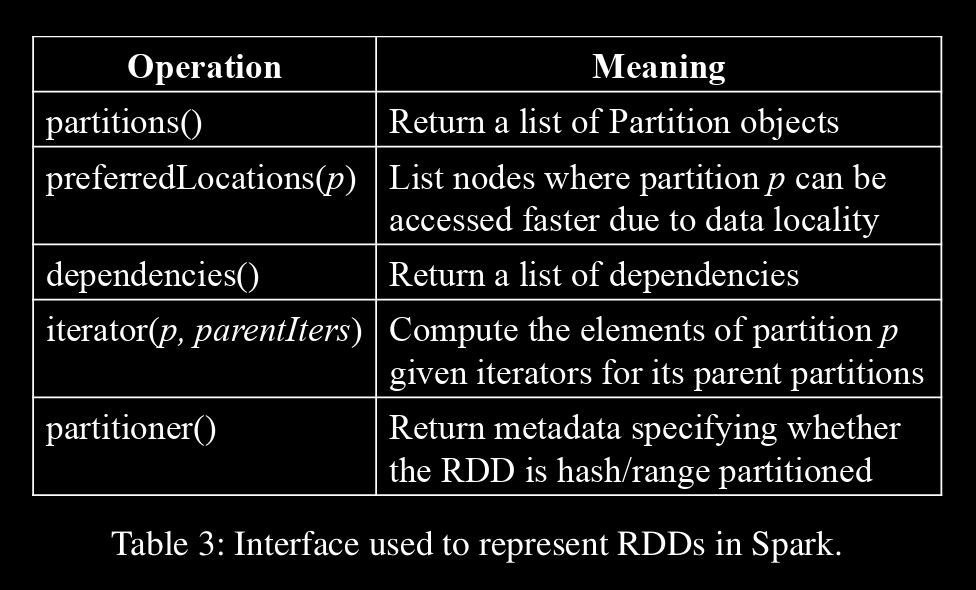
→ we propose representing each RDD through a common interface that exposes five pieces of information
and dependencies are classified into two types
- narrow dependencies, where each partition of the parent RDD is used by at most one partition of the child RDD
- narrow dependencies allow for pipelined execution on one cluster node
- recovery after a node failure is more efficient with a narrow dependency
- wide dependencies, where multiple child partitions may depend on it.
map leads to a narrow dependency, while join leads to to wide dependencies
Implementation
→ Each Spark program runs as a separate Mesos application, with its own driver (master) and workers, and resource sharing between these applications is handled by Mesos.
Job Scheduling
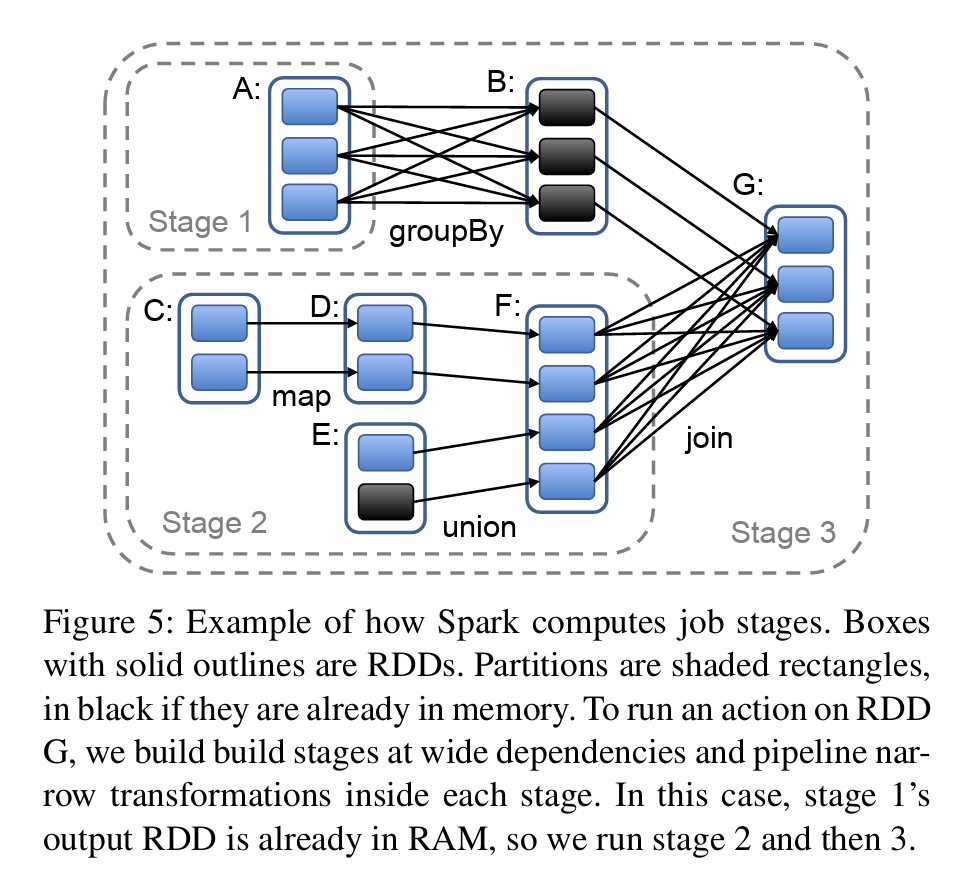
Whenever a user runs an action (e.g., count or save) on an RDD, the scheduler examines that RDD’s lineage graph to build a DAG of stages to execute
delay scheduling : improving data locality, task run on machine that already has the required input data in memory or on disk.
→ We do not yet tolerate scheduler failures, though replicating the RDD lineage graph would be straightforward.
Interpreter Integration
→ The Scala interpreter normally operates by compiling a class for each line typed by the user, loading it into the JVM, and invoking a function on it
→ This class includes a singleton object that contains the variables or functions on that line and runs the line’s code in an initialize method. For example, if the user types var x = 5 followed by println(x), the interpreter defines a class called Line1 containing x and causes the second line to compile to println(Line1.getInstance().x)
Class Shipping : worker nodes can fetch the bytecode for the classes over HTTP
Modified Code Generation : code generation logic is changed to refer the instance of each line object directly, where in general reference is not possible when a closure/func is serialized
Memory Management
- in-memory storage as deserialized Java objects
- faster than others
- in-memory storage as serialized data
- on-disk storage
LRU eviction policy to clear up space. In-mem partitions can get spilled to disk
Post-Read Thoughts
Further Reading
Ray- A Distributed Framework for Emerging AI Applications
Ownership- A Distributed Futures System for Fine-Grained Tasks Ray
Apache Flink- Stream and Batch Processing in a Single Engine