Spark: Cluster Computing with Working Sets
- Notation Legend
- Pre-Read Thoughts
- Introduction
- Programming Model
- Examples
- Implementation
- Results
- Related Work
- Post-Read Thoughts
- Further Reading
Notation Legend
#something: number ofsomething
→: excerpt from paper
(): an opinion or some information that’s not present in paper
Pre-Read Thoughts
(same “Pre-Read Thoughts” from Apache Spark- A Unified Engine for Big Data Processing)
At the time of writing (Mid 2025), Databricks, as a business org, is in it’s golden phase because of the obvious reason, “Apache Spark”
I feel Databricks achieved what Cloudera wanted to become, as Spark almost became synonymous with “Data Engineering”
Personally, I’ve used Spark just to get know about it, nothing professional so not too deep
(paper seems almost same on high level as article which is linked above, reading as RDD paper’s prerequisite)
Introduction
So far tools achieve scalability and fault tolerance by managing user defined acyclic graph data flows i.e., user doesn’t manage or handle faults, it’s the tool/sys
MapReduce, the pioneer, is inefficient in doing iterative work (like ML jobs) and analytics (like querying data warehouse). Addressing these inefficiencies, Spark was born.
→ The main abstraction in Spark is that of a resilient distributed dataset (RDD), which represents a read-only collection of objects partitioned across a set of machines that can be rebuilt if a partition is lost.
RDDs follow this property called lineage, which means building an RDD, when it’s lost, by following same steps of how it was built in past
Programming Model
→ Spark provides two main abstractions for parallel programming: resilient distributed datasets and parallel operations on these datasets (invoked by passing a function to apply on a dataset)
RDDs
→ A resilient distributed dataset (RDD) is a read-only collection of objects partitioned across a set of machines that can be rebuilt if a partition is lost.
RDDs can be created in 4 ways
- a file in distributed fs like hdfs
- parallezing a scala collection (distributing array slices to multiple nodes)
- transforming an RDD
- persisting an RDD which are ephemeral by default (similar to 1?)
- cache and save operations
Parallel Operations
reduce: Combines dataset elements using an associative function to produce a result at the driver program.
collect: Sends all elements of the dataset to the driver program. For example, an easy way to update an array in parallel is to parallelize, map and collect the array.
foreach: Passes each element through a user provided function. This is only done for the side effects of the function (which might be to copy data to another system or to update a shared variable as explained below).
Shared Variables
Broadcast variables: a large read-only piece of data (e.g., a lookup table), which is sent to worker node only once to save transfer costs
Accumulators: variables that workers can only “add”, and that only the driver can read.
-
accumulator code example
from pyspark import SparkContext sc = SparkContext("local", "AccumulatorExample") # Create an accumulator initialized to 0 error_count = sc.accumulator(0) # Sample data (could be loaded from a file) lines = sc.parallelize([ "INFO: operation successful", "ERROR: something failed", "INFO: all good", "ERROR: another failure", ]) # Transformation that uses the accumulator def count_errors(line): if "ERROR" in line: error_count.add(1) return line # Apply transformation (accumulator updated here) processed = lines.map(count_errors) # Trigger the computation (e.g., action like count or collect) processed.collect() # Now the accumulator holds the count of error lines print(f"Number of error lines: {error_count.value}")
Examples
(look up for examples in annotated pdf)
Implementation
→ Spark is built on top of Mesos (Mesos- A Platform for Fine-Grained Resource Sharing in the Data Center)
Datasets will be stored as a chain of objects capturing the lineage of each RDD, shown in Figure 1.
Each dataset object contains a pointer to its parent and information about how the parent was transformed.
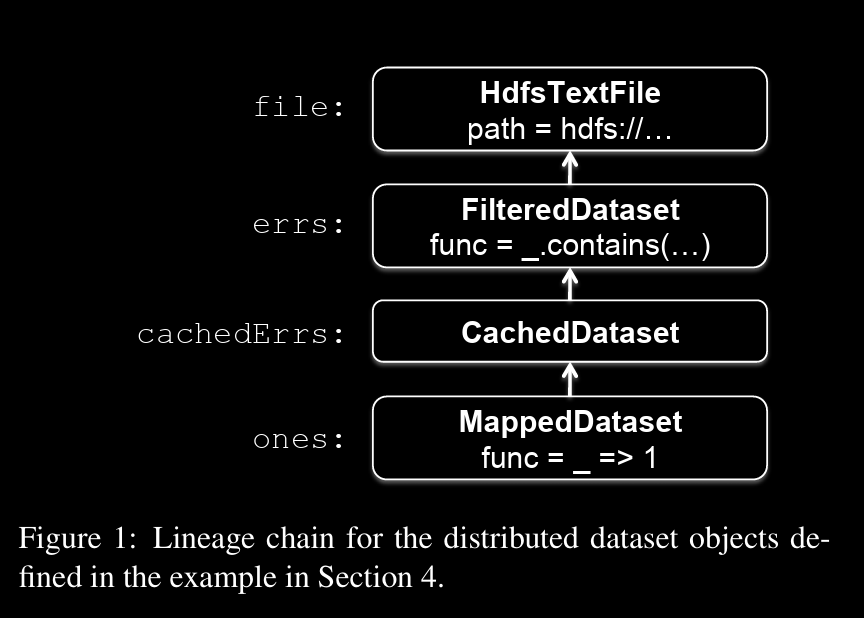
→ each RDD object implements the same simple interface, which consists of three operations:
getPartitions, which returns a list of partition IDs.getIterator(partition), which iterates over a partition.getPreferredLocations(partition), which is used for task scheduling to achieve data locality.
each worker get a partition allocated (allocation numbers depend on workers to partitions and something called delay scheduling for better data locality) as task
broadcast variables are pretty straight forward, hit the cache if missed, then hit the source like hdfs
Interpreter Integration
→ Scala interpreter normally operates by compiling a class for each line typed by the user. This class includes a singleton object that contains the variables or functions on that line and runs the line’s code in its constructor. For example, if the user types var x = 5 followed by println(x), the interpreter defines a class (say Line1) containing x and causes the second line to compile to println(Line1.getInstance().x)
- We made the interpreter output the classes it defines to a shared filesystem, from which they can be loaded by the workers using a custom Java class loader.
- We changed the generated code so that the singleton object for each line references the singleton objects for previous lines directly, rather than going through the static
getInstancemethods. This allows closures to capture the current state of the singletons they reference whenever they are serialized to be sent to a worker. If we had not done this, then updates to the singleton objects (e.g., a line settingx = 7in the example above) would not propagate to the workers.
Results
Related Work
Post-Read Thoughts
Simple paper, adds slightly more overview than article (again, article is from future i.e., 2016)
The next paper on RDDs, which has curr spark paper as prerequisite, should be interesting and deeper
Further Reading
Resilient Distributed Datasets- A Fault-Tolerant Abstraction for In-Memory Cluster Computing Spark