Dynamo: Amazon’s Highly Available Key-value Store
- Pre-Read Thoughts
- System Architecture
- Implementation
- Experiences & Lessons Learned
- Post-Read Thoughts
- Further Reading
Pre-Read Thoughts
The very first paper I wanted to read, but MapReduce took that privilege (no regrets)
I encountered this paper so many times as suggestion, but decided explicitly when researching on something and found this on reddit that S3 has index layer techniques of this paper
Later the inspirations from it like more popularly Zuck’s Cassandra, and less popularly NF’s Dynomite
I know that it uses DHTs but not how, that’s all
Worth mentioning, DynamoDB is influenced by Dynamo, but not the pure implementation and there are architectural diffs
System Architecture
System Interface
get(key) → returns object or list of conflicting objects along with context
put(key, context, obj) → context (not seen by caller) encodes system metadata + version numbers
md5(key) decides the node
Partition Algorithm & Replication
Consistent hashing
benefit is that only adjacent nodes are effected when new node is added or removed
a physical node is divided into several virtual nodes, this will mitigate hot partitions
nodes replicate keys with clockwise successor nodes based on a configurable replication factor N
Here in picture, Keys b/w A and B are replicating to C, D as well (apart from getting stored in B)
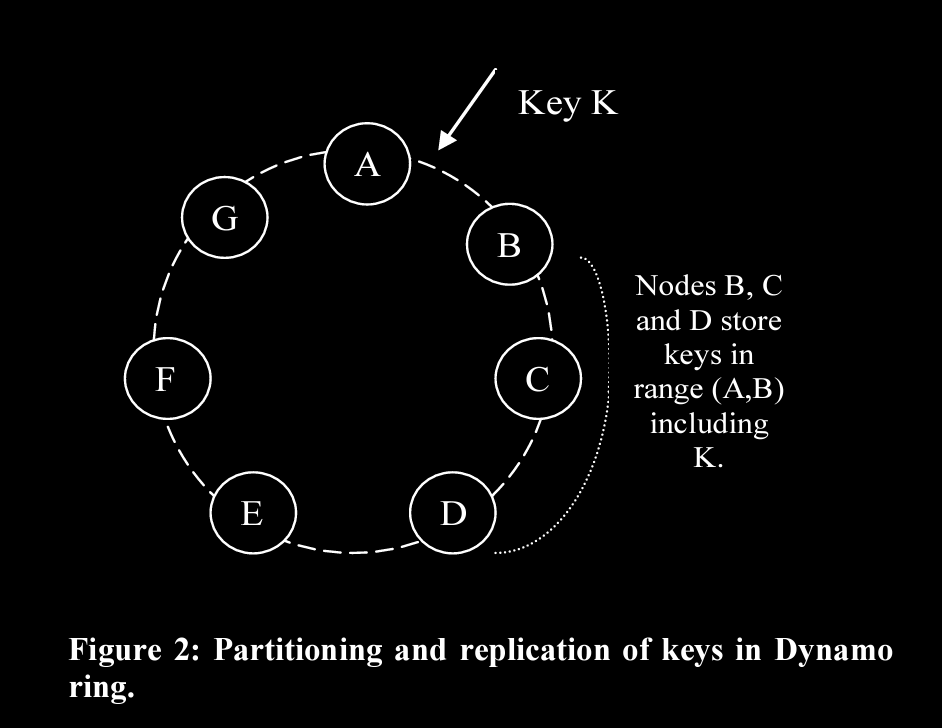
A preference list is maintained which contains mapping of keys to locations (physical nodes)
Data Versioning
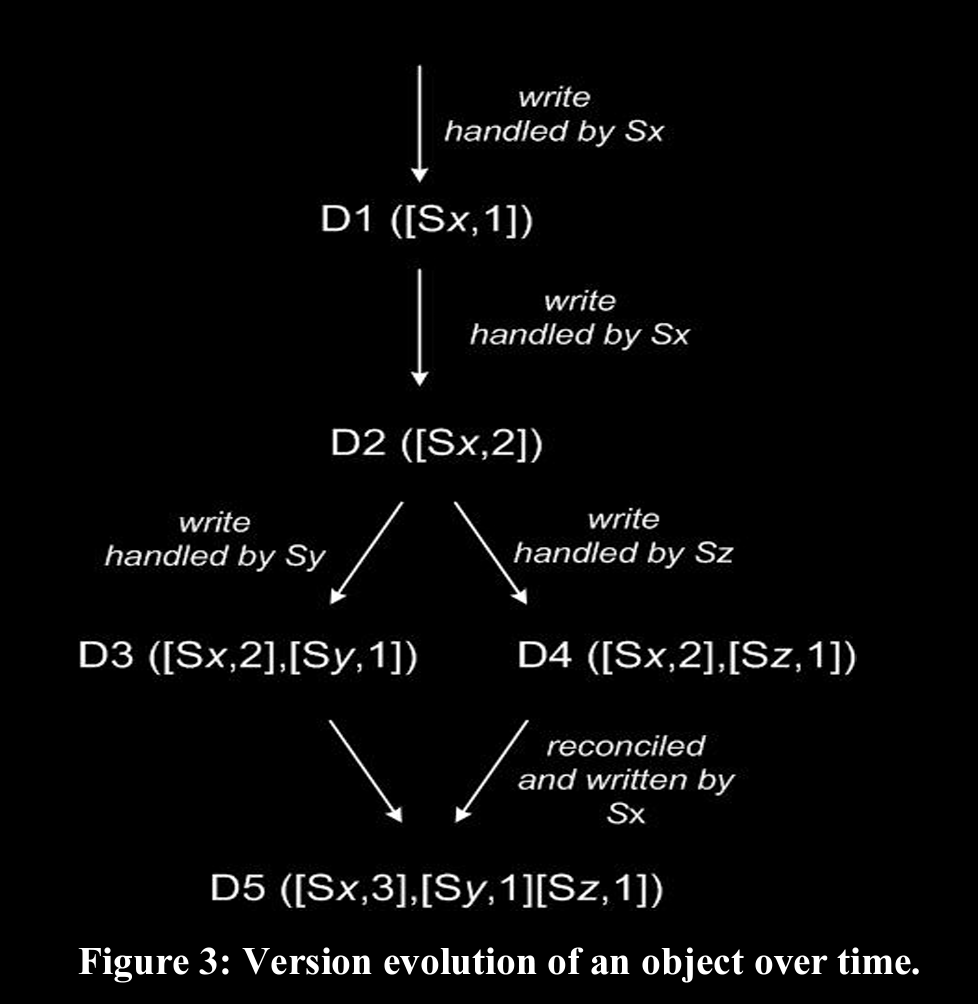
based on eventual consistency and usage of vector clocks for reconciliation (restoring state)
when updating an obj, client should specify the version it’s updating in req’s context (contains vector clock info)
when getting an obj, if there are multiple conflicted versions that Dynamo can’t resolve, all are sent in resp with version information
D5 from left image will be sent when read by a client in that scenario
to handle the over accumulation of vector clocks, it follows FIFO for truncation with some threshold
but it’s unlikely to happen usually because, writes always go to one of the top N nodes on preference list
Execution of get() and put() operations
selecting a node to send req to
- LB, overhead
- keep a list at client itself and send directly
node handling op.s (from top N nodes which are online in preference list) is called coordinator
when using an LB, if non coord node receives req, it’ll be forwarded
follows typical quorum system with R + W > N
R = Read Nodes, W = Write Nodes, N = Replication Factor
during put(), coord generates vector clock with new version locally and when W-1 nodes do op as sent by coord, it’s considered successful
during get(), it’ll ask similarly top N nodes, if there are version conflicts, coord will return all versions
Handling Failures: Hinted Handoff & Replica Synchronization
Sloppy Quorum (relaxed/not so strict)
relaxed as in, R and Ws can happen in diff replicas not the same replicas again
Hinted handoff is done i.e., when replica A is down, other replica B (hinted replica) will take it’s req.s on behalf of A. When A’s online again, B’ll deliver/handoff all those req.s
to check inconsistencies b/w replicas, merkle trees are used
if the hash values of the root of two trees are equal, then the values of the leaf nodes in the tree are equal and the nodes require no synchronization.
Membership and Failure Detection
An administrator uses a command line tool or a browser to connect to a Dynamo node and issue a membership change to join a node to a ring or remove a node from a ring
A gossip-based protocol propagates membership changes and maintains an eventually consistent view of membership
partitioning and placement information also propagates via the gossip-based protocol and each storage node is aware of the token ranges handled by its peers.
Decentralized failure detection protocols use a simple gossip-style protocol that enable each node in the system to learn about the arrival (or departure) of other nodes.
Implementation
After the read response has been returned to the caller the state machine waits for a small period of time to receive any outstanding responses. If stale versions were returned in any of the responses, the coordinator updates those nodes with the latest version.
This process is called ==read repair== because it repairs replicas that have missed a recent update at an opportunistic time and relieves the anti-entropy protocol from having to do it.
the coordinator for a write is chosen to be the node that replied fastest to the previous read operation which is stored in the context information of the request
Experiences & Lessons Learned
from reference pdf
Post-Read Thoughts
Paper picks up from Dynamo- Amazon’s Highly Available Key-value Store, I think the methods used in components are already mainstream — at present — like Consistent Hashing, Hinted Handoff, Replication
One of the lengthiest experiences part, I’ve seen so far.
very smooth read
Further Reading
DynamoDB
https://www.amazon.science/latest-news/amazons-dynamodb-10-years-later
Amazon DynamoDB- A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service